
- A+
这篇文章提出了一种基于图神经网络的通用模型Devign,通过学习丰富的代码语义集以进行图级分类。它包括一个新的Conv模块,用于在丰富的节点表征中有效提取有用的特征。数据集基于4个多样化的大规模开源C项目,为高复杂度和多样化的真实源代码。评估结果显示,Devign与现有技术相比,平均准确率提高了10.51%,F1值提高了8.68%,其中Conv模块在平均准确率上增加4.66%,F1值增加6.37%。

1 提出问题
1.1 传统机器学习算法的不足
机器学习算法将专家人工定义的特征或模式作为检测漏洞的输入,然而产生漏洞的根本原因因漏洞和库的类型而异,因此通过此方法来描述众多库中的所有漏洞是不切实际的。
1.2 目前基于神经网络方法的不足
最近的基于深度神经网络的方法在学习全面的程序语义以描述真实源代码中的高多样性和复杂性的漏洞方面都有很大的局限性。主要表现如下:
- 在学习方法方面,将源代码视为类似自然语言的平面序列,或仅用部分信息表征。然而,源代码实际上比自然语言更具结构性和逻辑性,并且具有抽象语法树(AST)、数据流、控制流等表示。此外,漏洞有时是微妙的缺陷,需要从语义的多个维度进行全面调查。目前方法的缺陷限制了其覆盖各种漏洞的潜力。
- 在数据集方面,使用简单的人工代码,即使用"good"或"bad"来区分漏洞代码和非漏洞代码,与复杂的真实代码相比存在较大差距。
2 解决方案
2.1 提出方法
针对上述问题,文章提出了一种新的基于图神经网络的模型,该模型针对真实漏洞数据进行复合编程表示,对编程代码语义进行编码,以捕捉各种漏洞特征。关键创新为提出的Conv模块,它从门控递归单元中获取图的异质节点特征作为输入,并利用传统的卷积层和密集层,分层次地选择更多的粗略特征,进行图层分类。
2.2 主要贡献
文章的主要贡献如下:
- 以AST为主,将不同级别的程序控制和数据依赖性编码为异质边的联合图,综合表示有助于捕获更广泛的漏洞类型和模式,并能通过图神经网络学习更好的节点表示。
- 提出带有Conv模块的GGNN模型,Conv模块从节点特征中分层学习,以捕获更高层次的图级分类任务的表征。
- 与基线方法相比,Devign的平均准确率提高10.51%,F1得分提高8.68%。同时,Conv模块的平均精度增益4.66%,F1增益为6.37%。与知名的静态分析器进行比较,Devign在所有数据集上的平均F1得分显著提升27.99%。将Devign应用于从4个项目中收集的40个最新CVE漏洞,实现了74.11%的准确率。
3 模型介绍
Devign可以划分为三个部分:1)复合代码语义的图嵌入层,将源代码编码为具有综合语义的联合图结构。2)门控图递归层,通过聚集和传递图中相邻节点的信息来学习节点的特征。3)Conv模块,提取用于图级预测的有意义的节点表示。

3.1 问题公式化
Devign在函数细粒度级别分析漏洞,并将漏洞函数的识别问题转化为二元分类问题,即给定一个函数,判断其是否存在潜在漏洞。将一个数据样本定义为\( \left(\left(c_{i}, y_{i}\right) \mid c_{i} \in\right.\left.\mathcal{C}, y_{i} \in \mathcal{Y}\right), i \in{1,2, \ldots, n}.\),其中\(C\)表示函数的集合,
\[\min \sum_{i=1}^{n} \mathcal{L}\left(f\left(g_{i}(V, X, A), y_{i} \mid c_{i}\right)\right)+\lambda \omega(f)\]
3.2 复合代码语义的图嵌入层
图嵌入层将函数代码\(c_{i}\)映射为可供模型输入的图数据结构,表示如下:
\[g_{i}(V, X, A)=E M B\left(c_{i}\right), \forall i={1, \ldots, n}\]
图2展示了一个存在整数溢出漏洞的代码表示为联合图结构的例子,该图在传统的三种代码表征结构(即AST、控制流和数据流图)的基础上,另外加入了源代码的自然序列。
- 抽象语法树(AST)展示代码的语法结构。蓝色框为AST叶节点,紫色箭头表示父子关系。
- 控制流图(CFG)描述了程序在执行过程中遍历的所有路径。图2中绿色箭头表示CFG的边。
- 数据流图(DFG)表示程序中变量的使用情况,数据流是面向变量的,任何数据流都涉及对某些变量的访问或修改。图2中橙色箭头表示DFG的边。
- 使用自然代码序列(NCS)边来连接AST中的相邻代码标记,保留了源代码序列所反映的编程逻辑。NCS边缘在图2中用红色箭头表示,连接AST的所有叶节点。
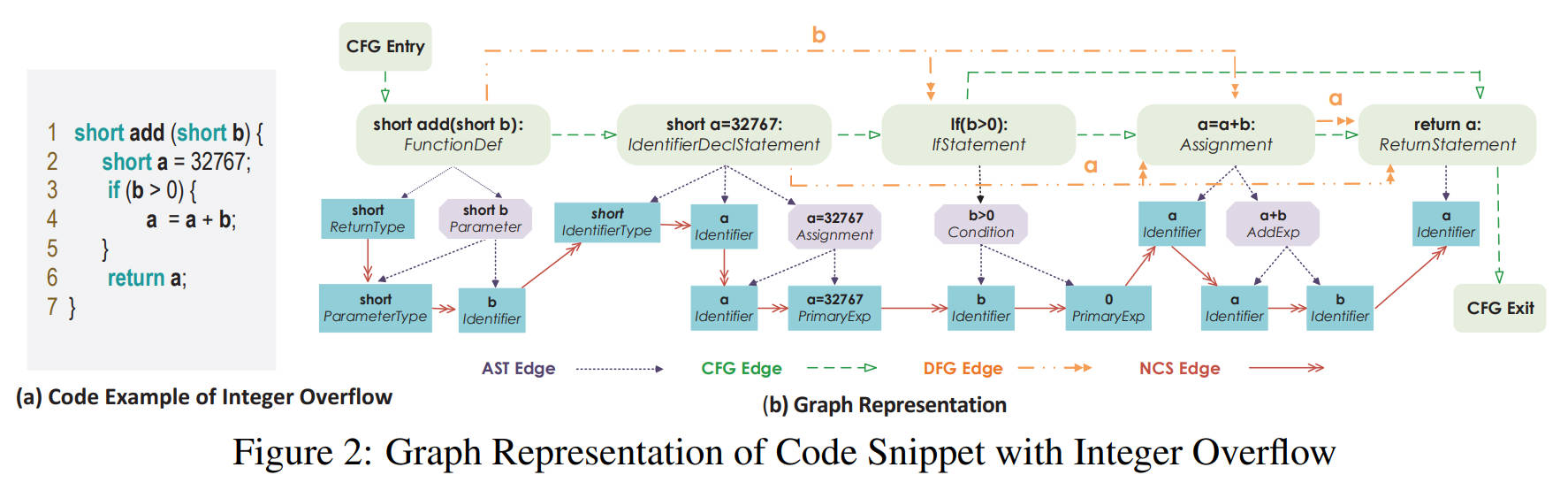
最终一个函数\(c_{i}\)可以表示为4种类型的子图共享一组节点\(V\)得到的联合图\(g\)。每一个节点有两个属性,代码和类型。代码即节点表示的源代码,类型即节点的属性。利用预训练模型word2vec对源代码以及类型编码,并将两种编码连接起来,作为最终的节点表征\(x_{v}\)。
3.3 门控图递归层
图神经网络的关键思想是通过邻域聚合嵌入局部邻域的节点表示。基于聚集邻域信息的不同技术,有图卷积网络、GraphSAGE、门控图递归网络及其变体。文章选择门控图递归网络来学习节点嵌入,因为它允许比其他两个更深,并且更适合具有语义和图结构的数据。
3.4 Conv层
标准图分类方法将所有生成的节点嵌入全局收集,并使用线性加权求和来平摊所有嵌入,这种方法不利于在整个图上进行有效分类。\(Conv\)模块可以选择与当前图级任务相关的节点和特征。每个代码表示图都有其预定顺序和相邻矩阵中编码的节点的连接,节点特征是通过门控图递归层学习的,而不是来自不同通道的分类节点特征的图卷积网络。因此,文章应用一维卷积和密集神经网络来学习与图级任务相关的特征,以实现更有效的预测。
\[\sigma(\cdot)=MAXPOOL(\operatorname{Relu}(CONV(\cdot)))\]
设\(l\)为应用的卷积层的数量,则\(Conv\)模块可以表示为:
\[Z_{i}^{(1)}=\sigma\left(\left[H_{i}^{(T)}, x_{i}\right]\right), \ldots, Z_{i}^{(l)}=\sigma\left(Z_{i}^{(l-1)}\right)\]
\[Y_{i}^{(1)}=\sigma\left(H_{i}^{(T)}\right), \ldots, Y_{i}^{(l)}=\sigma\left(Y_{i}^{(l-1)}\right)\]
\[\tilde{y}{i}=\operatorname{Sigmoid}\left(A V G\left(M L P\left(Z{i}^{(l)}\right) \odot M L P\left(Y_{i}^{(l)}\right)\right)\right)\]
首先应用传统1维卷积和密集层分别串联\(\left[H_{i}^{(T)}, x_{i}\right]\)和最终节点特征\(H_{i}^{(T)}\),然后在两个输出上进行对位相乘,然后在结果向量上进行平均聚集,最后进行预测。
4 实验评估
4.1 数据预处理
文章中提取数据集包含两种方式:
- 修复漏洞的提交(VFCs)。从提交中所做修订之前版本的源代码中提取出易受攻击的函数。
- 非漏洞修复提交(non-VFCs)。从修改前的源代码中提取非漏洞函数。
由于只有极小部分的提交是与漏洞相关的,需排除与安全无关的提交。其余与安全相关的,则进行人工标注。给定一个VFC或者non-CFC,根据修改后的函数,在提交前提取这些函数的源代码,并分配相应的标签。
4.2 生成图
使用C/C++代码分析工具Joern生成每个函数的AST和CFG, 由于原始DFG边被标记为所有涉及的变量,增加了边类型的数量,使嵌入的图复杂化,因此文章中将DFG替换为其他三种关系,即最近读取(DFG_R)、最近写入(DFG_W)和赋值计算(DFG_C),以使其更适合于图嵌入。同时为了计算效率,删除节点数量大于500的函数(占比15%)。
4.3 结果分析
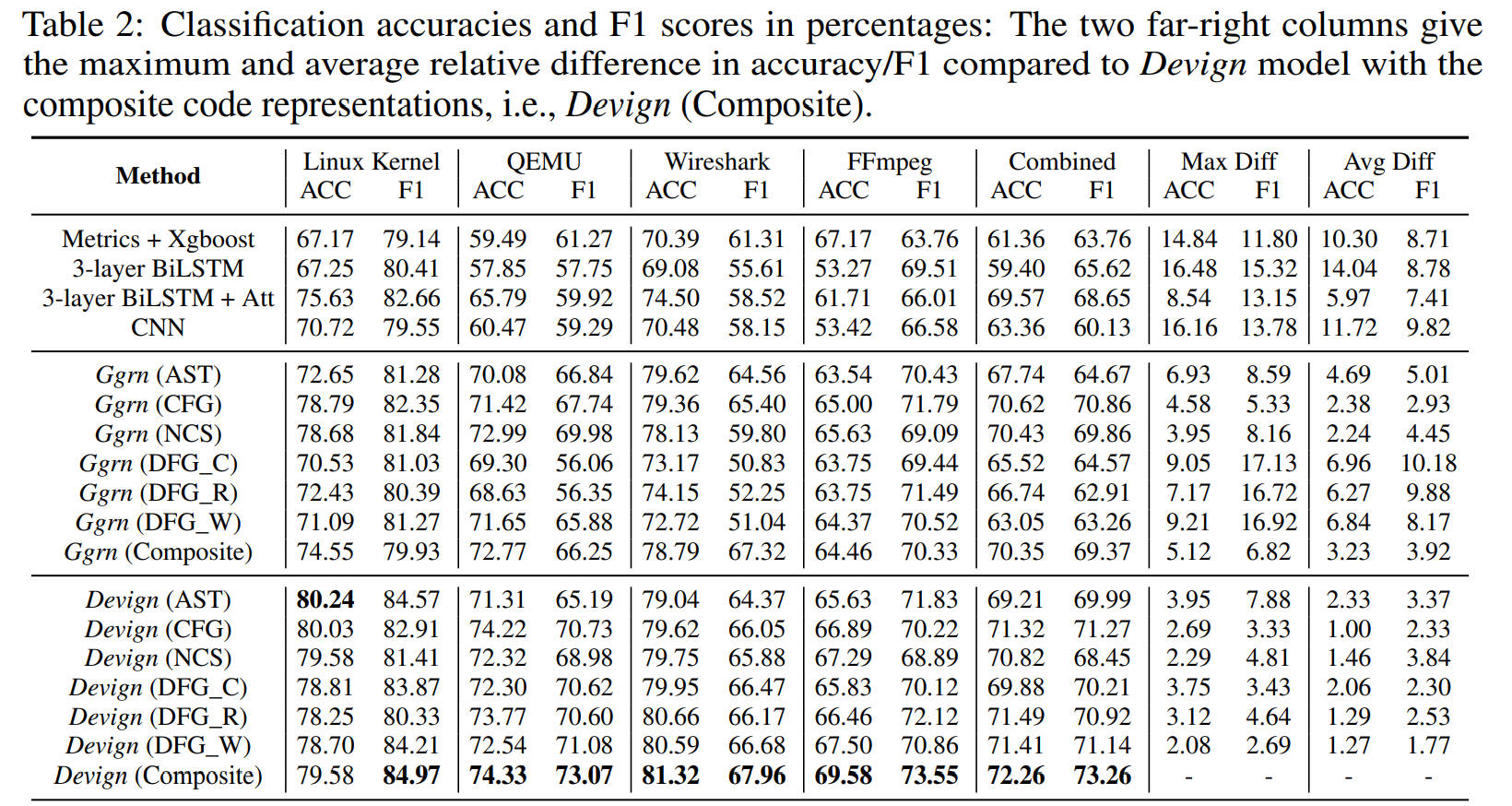
文章采用准确率(accuracy)和F1值来衡量性能,并执行5个实验来验证Devign发现漏洞的能力。与基线方法相比,Ggrn与Devign都显著优于基线方法。特别是,Devign的相对准确度提高平均10.51%,在QEMU数据集上至少为8.54%。Devign(Composite)在F1得分方面也优于4种基线方法,即F1得分的平均相对增益为8.68%,每个数据集的最小相对增益分别为2.31%、11.80%、6.65%、4.04%和4.61%。由于Linux遵循编码风格的特点,Devign的F1得分为84.97,在所有数据集中最高。
与\(Ggrn\)相比,在复合代码表示中,Devign比Ggrn拥有更高的精度(平均3.23%),其中FFmpeg数据集的最高精度增益为5.12%。此外,Devign在F1值上平均比Ggrn高3.92%。我在单个代码表示表示中,Devign显著优于Ggrn,其中DFG_W边缘的最大精度增益为9.21%,DFG_C的最大F1增益为17.13%。总体而言,与Ggrn相比,Devign的平均准确率和F1增益分别为4.66%和6.37%,这表明Conv模块提取了更多的相关节点和特征用于图级预测。
为了判断Devign是否可以学习不同类型的代码表示以及复合图的性能。表二结果显示,对于Ggrn,某些特定类型的边的精度甚至略高于复合图,例如,CFG和NCS图在FFmpeg和组合数据集上都有更好的结果。对于Devign,就准确性而言,除了Linux数据集之外,复合图表示总体上优于任何单边图,增益范围为0.11%至3.75%。在F1得分上,复合图与单边图相比平均提高了2.69%,说明复合图比单边图更有助于Devign学习更好的预测模型。
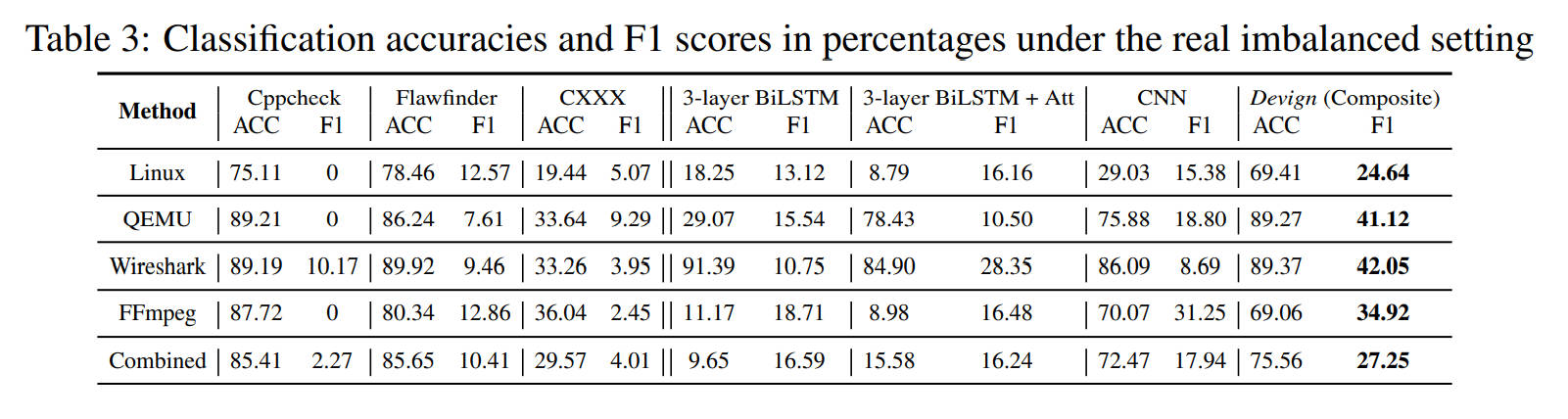
在真实不平衡数据集上与静态分析器比较,随机抽样测试数据,以创建具有10%脆弱函数的不平衡数据组。与著名的开源静态分析器Cppcheck、Flawfinder和商业工具CXXX进行比较。结果如表3所示,与所有分析器和所有数据集(单独和组合)的性能相比,Devign平均F1得分高27.99%。同时,静态分析器往往会漏掉最易受攻击的函数,并具有较高的误报率,例如,Cppcheck在4个单个项目数据集中的3个中发现了0个漏洞。
测试Devign能否发现通过CVE公开报告的最新漏洞。基于40个最新的CVE的提交,总共得到112个易受攻击的函数。将这些函数输入到经过训练的Devign模型中,平均准确率达到74.11%,这表明Devign在实际应用中有发现新漏洞的潜力。
5 个人总结
这篇文章提出了一种新的漏洞检测模型Devign,它能将源代码函数从多个语法和语义表示编码到联合图结构中,然后利用复合图表示来有效地学习并发现漏洞代码。但存在以下缺陷:
Devign存在的缺陷:
由于Devign是基于函数粒度,且在联合图结构上仅考虑500个图节点,这就会导致在一个函数很大时,其漏洞检测能力有限,存在较大的误差。因此,Devign不适用于大函数的源代码,这个时候可以考虑将大函数通过控制流和数据流切片,从而得到代码切片,然后对切片进行处理。
