
- A+
文中提出一种基于Transformer的行号级漏洞预测方法 LineVul,以解决最先进的 IVDetect 方法的若干局限性。该方法通过对包含 188k+ C/C++ 函数的大规模真实数据集进行实证评估,LineVul 实现了:(1)函数级预测的 F1-measure 提升160%-379%;(2)行号级预测的 Top-10 Accuracy 提升12%-25%;以及(3)E ffort@20%Recall 比基准方法低29%-53%。附加分析还表明,LineVul 在预测前 25 个最危险的 CWE 所影响的易受攻击函数也非常准确(75%-100%)。
1 问题描述
最近提出的一种基于图的粒度漏洞预测方法,IVDetect,存在以下局限性:
- IVDetect 的训练过程仅限于项目特定的数据集。
- IVDetect 方法中基于 RNN 的架构仍无法有效捕捉源代码中长期有意义的依赖关系和语义。
- IVDetect 的子图解释仍然是粗粒度的。
2 解决方案
文章贡献如下:
- LineVul 是一种基于Transformer的行号级漏洞预测方法,解决了现有漏洞预测方法的各种局限性。
- 验结果表明,与现有漏洞预测方法相比,LineVul 更准确、更经济、更有效。
在图 1 中,易受攻击的函数 unPremulSkImageToPremul 包含了一行易受攻击的行(即第九行),其中变量类型被错误地定义,并进一步导致了 CWE-787 漏洞类型。IVDetect 生成了 PDG 子图,指出第 5 行、第7 行、第 8 行和第 9 行为易受攻击模式。另一方面,LineVul 直接指出了实际的易受攻击行。
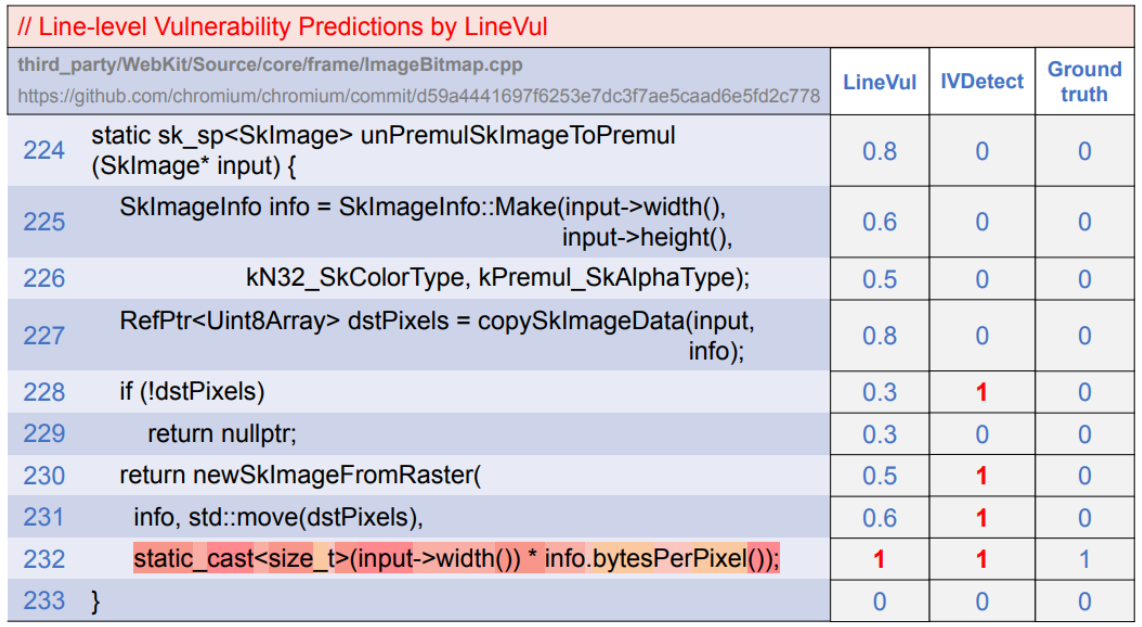
图1 研究动机
3 方法设计
LineVul 方法分为两个阶段:预测漏洞函数和定位漏洞代码行,图2为LineVul的大致架构。
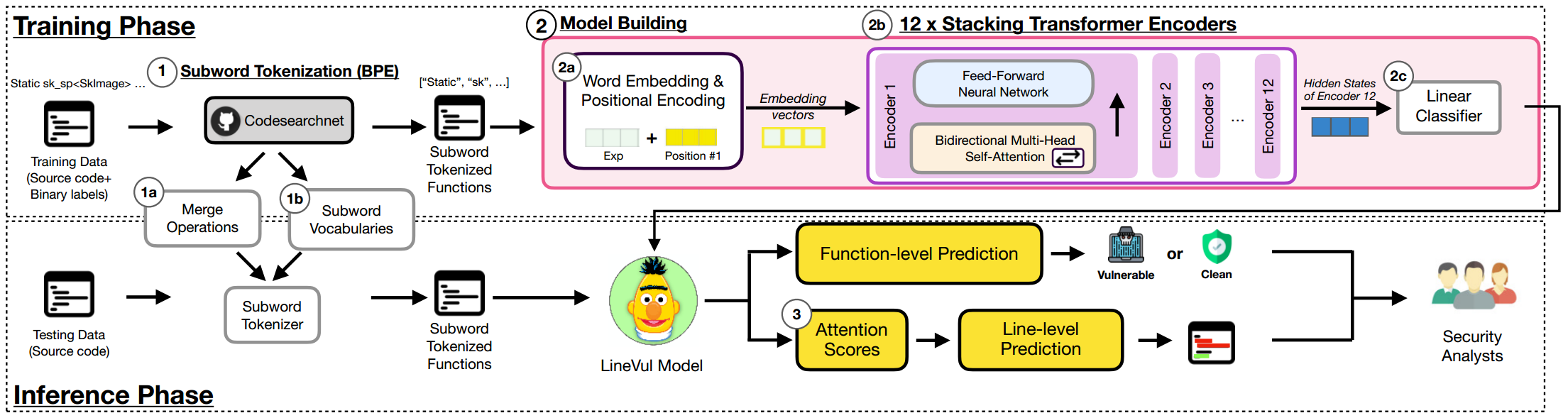
图2 LineVul整体架构图
3.1 函数级漏洞预测
BPE子词标记化。BPE 会将所有单词分割成字符序列,并找出最常出现的符号对(例如,两个连续字符对),将其合并为一个新符号。BPE 是一种将稀有词拆分成有意义的子词,同时保留常用词(即不将常用词拆分成更小的子词)的算法。比如函数名 "unPremulSKImageToPremul" 将被拆分为一串子词 ["un", "Prem", "ul", "Sk", "Image", "To", "Prem", "ul"]。常见的单词 "Image" 被保留,其它罕见的词被拆分。在对各种函数名进行标记化时,使用 BPE 子词标记化将有助于减少词汇量大小,因为它会将罕见的函数名分割成多个子组件,而不是直接将完整的函数名添加到字典中。文中在 CodeSearchNet 语料库中应用了 BPE 方法,以生成一个适用于源代码语料库预训练语言模型的子词标记化器。
LineVul模型构建。基于BERT架构并利用CodeBERT的初始权重建立了 LineVul 模型:(1)LineVul 对子词标记的函数进行词和位置编码,以生成每个词的嵌入向量及其在函数中的位置。(2)然后,将该向量输入 BERT 架构,该架构由 12 个 Transformer 编码器模块堆叠而成,每个编码器由多头自注意层和全连接前馈神经网络组成。(3)最后,输出的向量被送入一个线性层,以便对给定函数进行二元分类。
(1)词和位置编码。步骤的目的是生成编码向量,这些编码向量捕获token的语义及其在输入序列中的位置。为此,对于每个子词标记化的标记,生成两个向量:(1)单词编码向量,表示给定代码标记与其他代码标记之间的有意义关系;(2)位置编码向量,表示给定标记在输入序列中的位置。记号编码向量根据词嵌入矩阵Wte|V|xd生成,其中|V|为词汇表大小,d为嵌入大小。位置编码向量根据位置嵌入矩阵Wpecxd生成,其中c为上下文大小,d为嵌入大小。最后,将单词编码向量和位置编码向量连接起来,得到Transformer 编码器块的输入向量。
(2)具有双向自注意力机制的12个 Transformer 编码器。在这一步中,编码后的向量被送入一个由12个仅含编码器的 Transformer 模块组成的堆栈中(即BERT架构)。每个编码器块由两个组件组成,即双向多头自注意力层和全连接前馈神经网络。
(3)单个线性层。在堆叠 Transformer 编码器模块中建立了多个具有非线性激活函数(即 ReLU)的线性变换,因此最终编码器输出的表示是有意义的。只需要一个线性层来将代码表示映射成二进制标签,即 y = WTX + b。
3.2 行级漏洞定位
给定一个被 LineVul 预测为易受攻击的函数,利用 Transformer 架构内的自注意力机制来定位易受攻击的代码行,从而执行号级的漏洞定位。对预测贡献最大的令牌(token)很可能就是易受攻击的令牌,对于函数中的每个子词令牌,总结 12 个 Transformer 编码器块中其对应的自注意力得分。在获得关注的子词令牌分数后,将这些分数整合为行分数。通过换行控制字符(即 \n)将整个函数拆分成许多令牌列表(每个令牌列表代表一行代码)。最后,对于每个令牌得分列表,将其汇总为一个关注行得分,并按降序排列这些行得分,得分最高的行为易受攻击的代码行。
4 实验设计
文中实验旨在回答以下3个研究问题:
- LineVul 的函数级漏洞预测的准确性如何?
- LineVul 的行号级漏洞定位的准确率怎样?
- 对于行级漏洞定位,LineVul的成本效益是什么?
实验结果分别如下图所示。
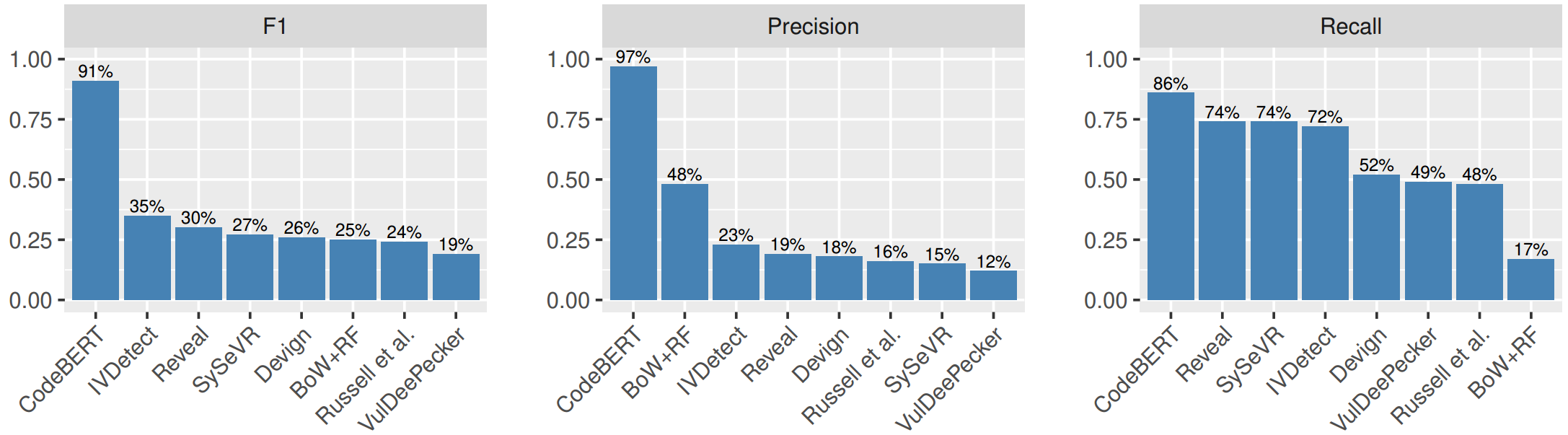
(RQ1)图3 LineVul和7个基线关于函数级漏洞预测实验对比的结果

(RQ2)图4 文中自注意力方法和其他五种方法的前10准确率和IFA值得对比
Top-10 Accuracy:在前十名排名中出现至少一个实际易受攻击代码行的易受攻击功能的百分比。
Initial False Alarm(IFA):安全分析人员需要检查的错误预测行(即,错误地预测为易受攻击或错误警报的非易受攻击行)的数量,直到找到给定函数的第一个实际易受攻击行。IFA被计算为安全分析师在发现第一个实际易受攻击的线路之前必须检查的假警报的总数。IFA值越低,说明安全分析人员在检查虚警上花费的精力越少。
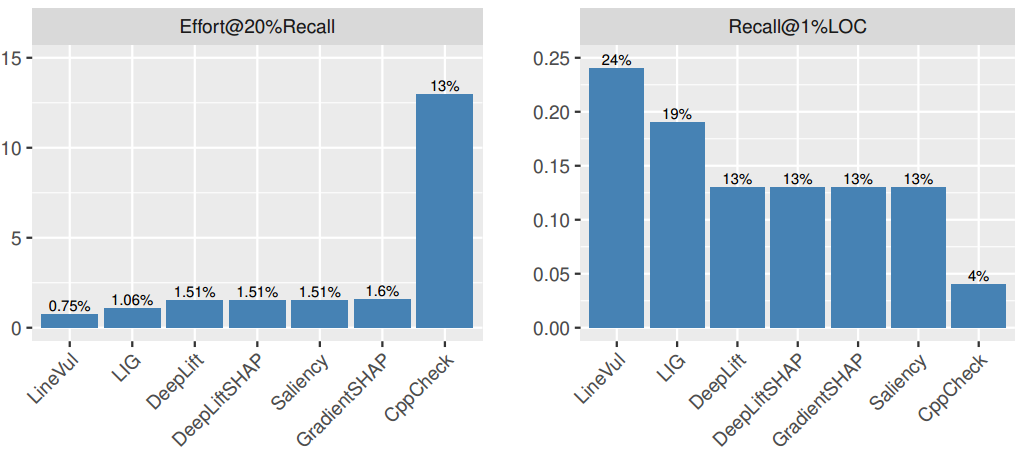
(RQ3)图5 自注意力方法和其它五种方法的Effort@20%Recall,Recall@1%LOC值对比结果
表1 LineVul的每个组件对函数级漏洞预测的贡献
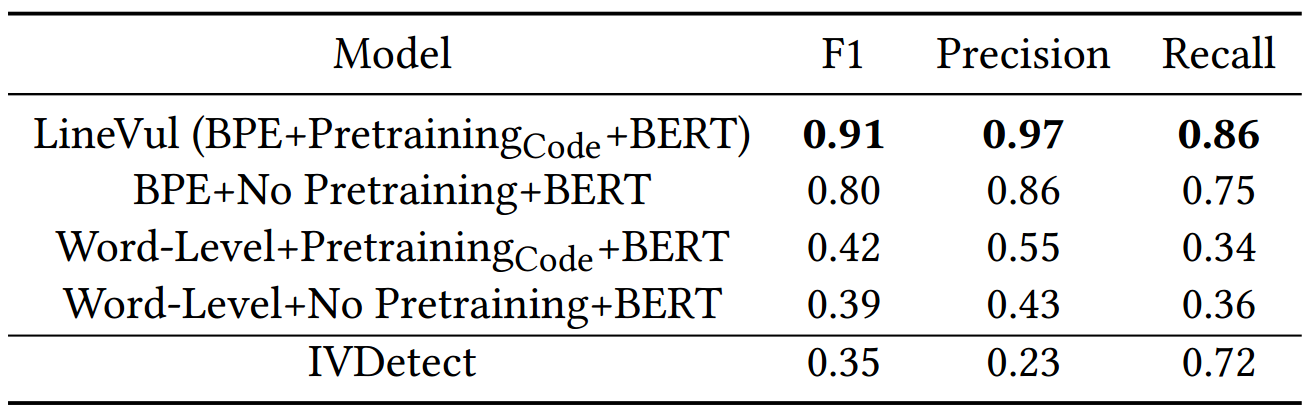
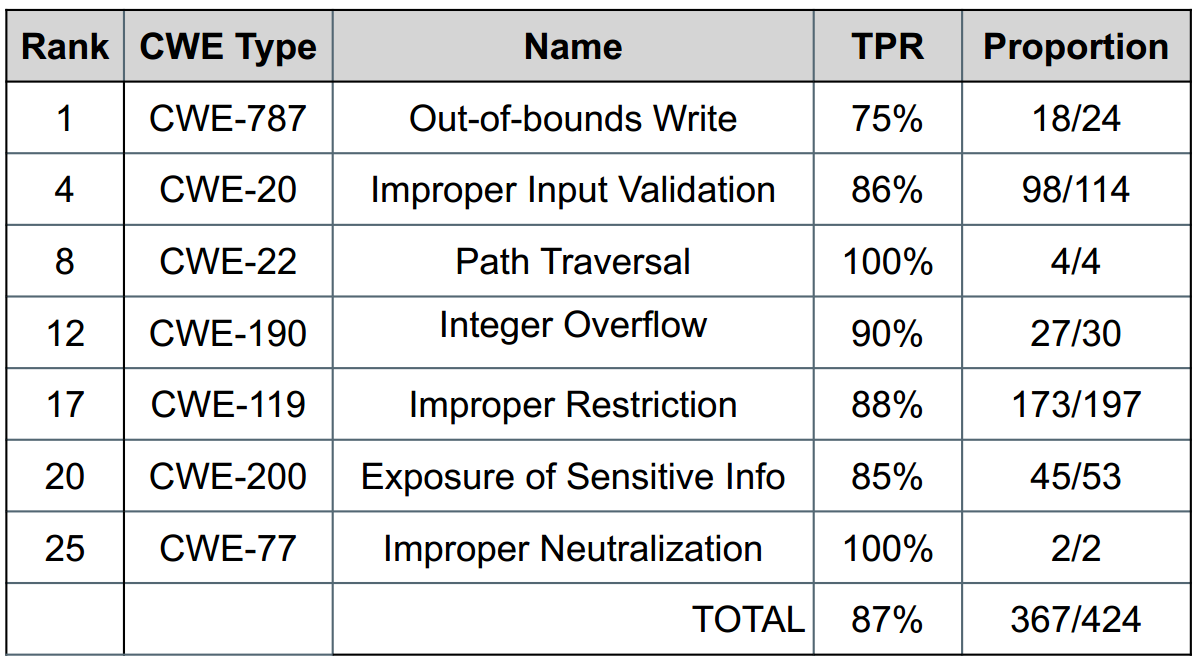
表2 LineVul对前25个最危险的CWEs检测的准确性
5 总结
文中提出了一种基于Transformer的漏洞预测方法LineVul,用于预测哪些函数以及哪些代码行存在漏洞。通过对一个包含 188k+ C/C++ 函数的大规模真实数据集进行实证评估,LineVul 在函数级预测上F1-measure 提升了160%-379%;在行号级预测上 Top-10 Accuracy 提升12%-25%;且Effort@20%Recall比最先进的方法低29%-53%。该研究结果表明,LineVul 比现有的漏洞预测方法更准确、更精细。
6 原文链接
论文题目:LineVul: A Transformer-based Line-Level Vulnerability Prediction
论文出处:2022 IEEE/ACM 19th International Conference on Mining Software Repositories (MSR)
