
- A+
近年来,人们提出了基于深度学习(DL)的漏洞检测系统,用于从源代码中自动提取特征。这些方法在合成数据集上可以实现理想的性能,但在检测真实世界的漏洞数据集时,准确率却大幅下降。此外,这些方法仅适用于单个函数,无法学习函数之间的信息。论文提出行为图模型并构建了新的框架 VulBG,用于提取函数中的抽象行为,表示函数之间的关系,并利用这些信息帮助基于 DL 的漏洞检测模型实现更高的性能。实验结果显示,VulBG 使(TextCNN、ASTGRU、CodeBERT、Devign 和 VulCNN)等基线模型检测到更多漏洞,提高了其整体检测性能。
1 问题描述
目前大部分方法将漏洞语义提取的工作留给了神经网络,这是不合适的,因为漏洞往往只存在于函数的一小部分。将整个函数传递给神经网络模型会引入与漏洞无关的大量信息。此外,现有方法只关注一个函数,忽略了函数之间的潜在联系。函数是实现某些功能的代码集合。即使两个函数实现的功能完全不同,它们的子任务中也可能存在共同的逻辑、算法和编程模式。
2 解决方案
论文将行为定义为代码中实现特定功能的逻辑、算法或编程模式,并将每个函数视为一组行为。因此,函数之间的联系可以通过它们各自的行为来解决。漏洞可能存在于一个行为中,也可能存在于一组行为中。建立了一个行为图模型(Behavior Graph Model)来连接不同函数的行为,并利用它来增强现有基于 DL 方法的检测能力。首先进行程序切片,将函数分割成一组切片,并将每个切片视为函数的一种行为。然后,根据不同函数中不同程序切片(即行为)的相似性计算,构建行为图。在获得全局行为图之后,采用节点嵌入技术将每个节点(即函数)转换为向量表示,作为函数的行为特征。论文的贡献如下:
- 提出了一种新思路,即从函数的源代码中提取抽象行为,并构建行为图(Behavior Graph),将不同函数的行为关联起来,从而辅助漏洞检测。
- 实现了 VulBG 框架,通过将行为图与其他基于 DL 的 VD 模型相结合,提高漏洞检测的性能。
- 对 VulBG 进行了评估,并选择了五个最先进的 VD 模型作为基线模型。实验结果表明,VulBG 提升了所有基线模型的漏洞检测性能。
论文按语义分割函数,提取函数的抽象行为,而不是试图获取包含完整易受攻击语义的切片。通过对潜在的易受攻击操作进行切分,将函数分解为多个片段。每个片段都包含函数的部分语义,将其视为函数的一个行为,然后可以用一组行为来表示函数。
3 系统架构
图 3 展示了 VulBG 的三个阶段:行为图构建、行为特征提取和模型融合。
- 行为图构建: 鉴于函数的源代码,使用切片和代码嵌入来获取函数的行为。通过对行为进行聚类,得到一组中心点行为,然后根据中心点行为和行为的相似性构建行为图。
- 行为特征提取:对每个函数节点进行图嵌入,将其转换为向量,然后使用多层感知器(MLP)进一步处理函数的行为特征。
- 模型融合:采用了模型融合的方法,将行为特征与(TextCNN、ASTGRU、CodeBERT、Devign 和 VulCNN)等模型提取的特征结合起来,共同进行分类。

图 3 VulBG 的基本架构
3.1 行为图构建
行为图旨在表示函数间的联系,由函数节点和行为节点质心(切片)构成,行为节点表示为聚类的质心,函数节点表示该行为的所属函数。
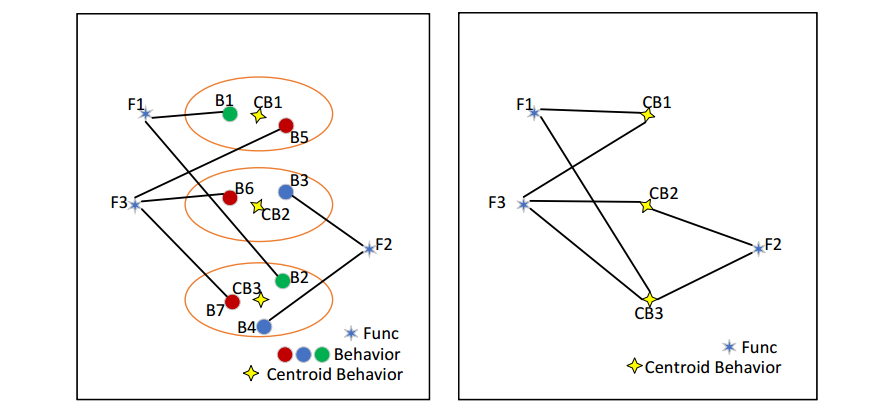
图 4 行为图示例
图 4 为一个行为图的实例。其中 B1、B2、...、B7 为各个函数的行为;CB1、CB2、CB3 为多个相似行为通过聚类后得到的质心;F1、F2、F3 为函数。用质心表示所有相似行为,并将函数与质心相连得到最终的行为图,其中 边 基于函数行为到质心的欧几里得距离 设置的权重。

图 5 行为图构建流程
图 5 展示了行为图的构建流程,大致可以分为 4 个部分:代码切片、代码嵌入、K-Means 聚类以及图构建。
3.1.1 代码切片
不同于常规的代码切片方法将完整的 源程序/函数 处理为单个切片,文中根据兴趣点/关注点将函数切分为多个切片(行为)。论文将漏洞关注点归纳为两点:
- API 调用:API 的误用可能会导致 BOF、UAF、IF 等漏洞。根据 API 函数的参数进行后向切片,根据该函数的返回值进行前向切片
- 内存操作:分为指针类型变量和数组类型变量,对这类操作进行后向切片。
基于上述两类兴趣点/关注点,对每一个函数执行代码切片。代码切片通过源代码分析工具 Joern 实现。切片所需要的数据流依赖和控制流依赖通过 Joern 生成的 PDG 和 CFG 获得,操作包含的变量通过 Joern 的查询结果得到。对于每一个待切分的变量,在对应的CFG 中向前和向后遍历,收集存在数据依赖的语句和变量。在生成的所有切片中,大约 95.8% 的切片少于 64 个单词。
3.1.2 代码嵌入
函数的行为表示为多个文本形式的代码切片。论文采用 CodeBERT 模型对函数行为进行嵌入,它可以获取代码序列的长距离依赖关系,并使模型关注代码序列中的重要部分(多头注意力机制)。在论文中,每一个行为(切片)被编码为一个长度为 768 维的向量。
3.1.3 聚类
如果直接以一个源程序中的所有行为构建图,那么该图会很复杂、庞大,不利于后续处理。文中采用 K-Means 聚类算法中的特殊变种 MiniBatchKMeans 对提取到的一系列行为进行聚类,将多个相似的行为聚类为一簇,以减少图的节点向量,使信息更加聚集。
3.1.4 图构建
分别连接函数和其对应的行为,构建行为图。不同的行为之间存在差异,利用行为的相似性(行为节点到聚类质心的欧几里得距离)设置边的权重。两个行为越相似,它们的嵌入结果越相近。
3.2 行为特征提取
在得到行为图后,利用 Node2Vec 将行为图中的函数节点编码为长度为 128 维的向量,并将图向量输入到 4 层的 MLP 分类器中,输出最后一层隐藏层的值作为本文提取到的漏洞行为特征。
3.3 模型融合
如图 6 所示,在得到行为特征向量后,运行其它基线方法获取对应的特征向量,将二者进行 concatenate 融合,输入到输出层,得到最终的预测值。 论文中的基线方法包括 TextCNN、ASTGRU、CodeBERT、Devign、VulCNN 五种。
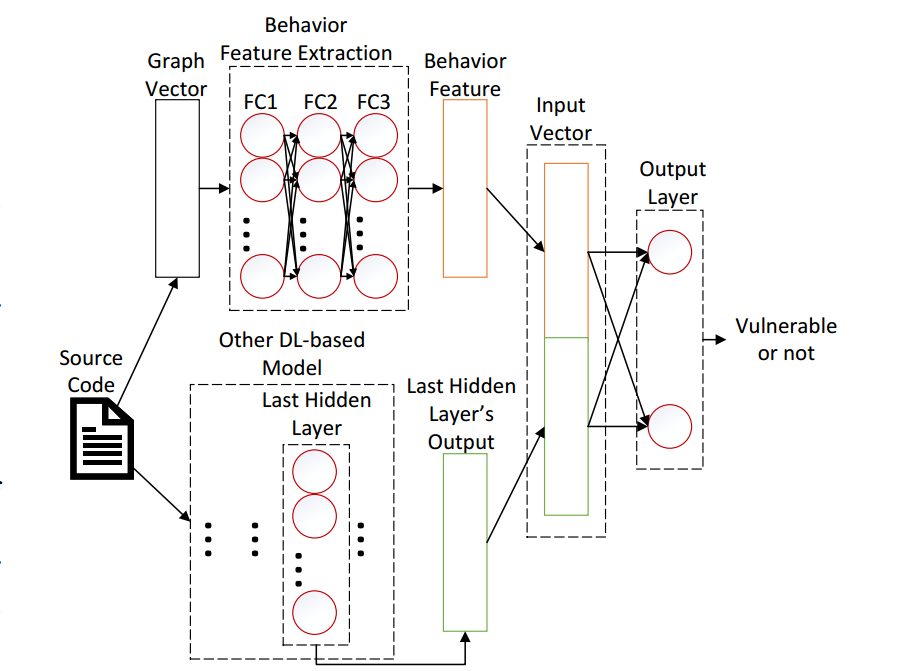
图 6 VulBG 模型融合架构
4 实验评估
4.1 实验设置
实验数据集采用两种真实世界的数据集:FFMpeg+Qemu (Devign),Chrome+Debian (Reveal)。数据集的详细信息如表 1 所示。
表 1 数据集统计

实验采用 Precision (P),Recall (R), F-measure (F1) 三个指标来评估 VulBG 的漏洞检测性能:
P = TP / TP + FP;R = TP / TP + FN;F1 = 2 * ( P * R / P + R).
其中 TP:true positive;FP:false positive;TN:true negative;FN:false negative.
4.2 实验评估
如表 2 所示, 行为图模型实现了较高的 F1(56.1%)和 Recall(61.2%)。就 F1 和 Recall 而言,在六种方法中,行为图模型在 FFMpeg+Qemu 数据集上排名第一,在 Chrome+Debian 数据集上排名第二,这已经证明行为图模型在漏洞检测中效果良好。
表 2 VulBG 与基线方法性能对比

如表 3 所示,各项指标的变化情况列于分数之下。所有融合模型的 F1 和 Recall 都较高。在 FFMpeg+Qemu 数据集上,除了 BG+TextCNN 的 Precision 外,各模型的所有指标都达到了更高的分数;在 Chrome+Debian 数据集上,除了 BG+CodeBERT 的 Recall 有所下降外,各模型的所有指标也都有所提高。
表 3 模型融合后的性能对比

总而言之,VulBG 对提高基于 DL 的 VD 性能有显著效果。平均而言,在 FFMpeg+Debian 数据集上,F1、精确度和召回率分别提高了 4.2%、0.1% 和 8.7%;在 Chrome+Debian 数据集上,F1、精确度和召回率分别提高了 6.5%、5.3% 和 1.7%。VulBG 的高召回率使基于 DL 的 VD 能够发现更多漏洞,而更高的 F1 也证明 VulBG 可以提高不同模型的整体性能。
5 总结
文中提出了一种新方法,它可以提取函数的行为,然后构建行为图来表示不同函数之间的联系。设计并实现了 VulBG,通过将行为图与其他基于 DL 的 VD 方法相结合来提高漏洞检测性能。在两个真实世界数据集上的评估结果表明,行为图本身就足以胜任漏洞检测工作,且 可以进一步有效提高不同类型基于 DL 的 VD 方法(即 TextCNN、ASTGRU、CodeBERT、Devign 和 VulCNN)的整体性能。
6 原文链接
论文题目:Enhancing Deep Learning-based Vulnerability Detection by Building Behavior Graph Model
论文出处:2023 IEEE/ACM 45th International Conference on Software Engineering ( ICSE 2023 )
