- A+

1 引言
软件漏洞检测对于确保网络安全至关重要。目前,大多数软件是以二进制形式发布的,因此研究人员只能通过分析二进制程序来检测这些软件中的漏洞。尽管现有的研究方法对二进制漏洞检测做出了重大贡献,但仍存在许多不足,如误报率高、检测粒度粗、依赖专家经验等。研究的目标是对二进制程序中的漏洞进行细粒度智能检测。因此提出了二进制程序的细粒度表示,并引入深度学习技术来智能检测漏洞。使用库/API函数调用的程序片来表示二进制程序。此外,设计并构造了一个二进制门控递归单元(BGRU)网络模型,以智能地学习漏洞模式并自动检测二进制程序中的漏洞。
2 文章贡献
- 提出通过分析数据流和控制流信息,使用与库/API函数调用相关的程序切片来表示二进制程序。该方法可以保留程序语句之间的语义信息,并可用于确定程序中漏洞的位置。
- 将深度学习引入基于静态分析的二进制代码漏洞检测,为二进制程序构建了一个深度学习漏洞检测模型,该模型可以自动学习二进制代码中的漏洞特征,并解决了传统方法主观性强的问题。
- 实现了一个称为BVDetector的方法原型。将BVDetector与其他最先进的方法进行了比较,BVDetector具有更低的假阴率和假阳率,这证实了BVDetector在二进制漏洞检测中的有效性。
3 方法介绍
3.1 系统概述
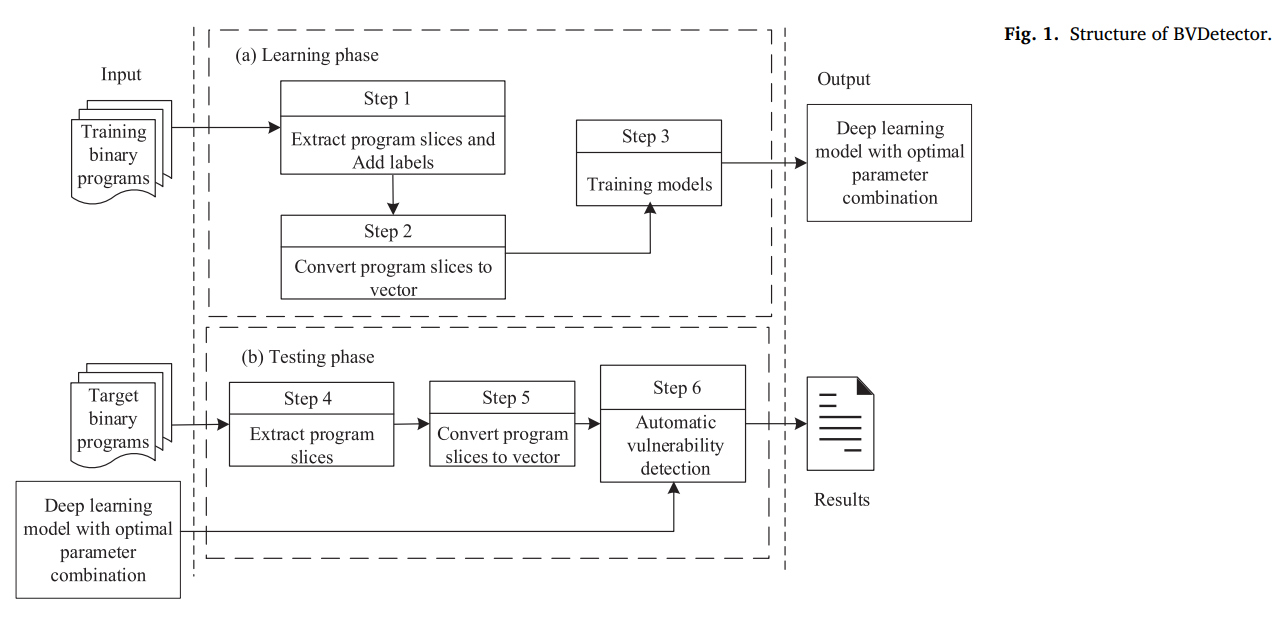
系统的总体结构如图1所示。它有两个阶段:学习阶段和检测阶段。在学习阶段,系统首先从训练二进制程序中提取程序切片,并向程序切片添加相应的标签。然后,系统将程序切片转换为用于训练神经网络模型的向量。最后,该系统训练了一个深度学习模型,可以自动识别二进制程序漏洞。在检测阶段,系统使用目标二进制程序测试训练模型,并评估其性能。
首先给出程序切片(program slice)的定义:一个程序切片 Si 由一串在语义上存在数据依赖或控制依赖的汇编代码行组成,表示为Si =(si1, si2, ......, sin),其中 sij 为 Si 中的第 j 行汇编代码。
选择程序切片作为检测目标有以下两点原因:
- 程序切片是从二进制程序获得的一组代码行,它比整个二进制程序具有更精细的粒度。此外,BVDetecter可以提取跨函数的切片,以获得更准确的结果。
- 通过二进制程序的数据流或控制流分析提取程序切片。因此,程序切片的代码行是语义相关的,这与将语义向量作为输入的深度学习一致。
3.1.1 学习阶段
如图1(a)所示,学习阶段分为3个步骤。
步骤1:提取程序切片并添加标签。
步骤2:将程序切片转化为向量。
步骤3:训练模型。
3.1.2 测试阶段
如图1(b)所示,测试阶段同样可分为3个步骤。
步骤1:提取程序切片。
步骤2:将程序切片转化为向量。
步骤3:自动化漏洞检测。
3.2 提取程序切片并添加标签
3.2.1 程序切片生成机制
首先,根据公布的漏洞规则,从基于CFG的二进制程序中提取库/API函数调用。然后,通过程序依赖性分析提取受库/API函数调用影响的所有语句。最后,这些语句共同构成程序切片。
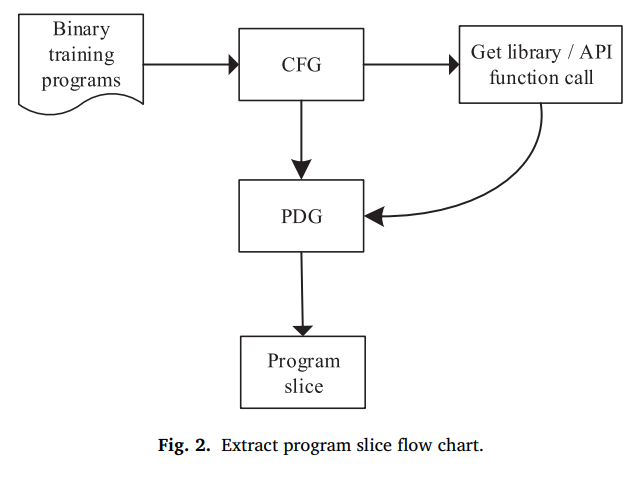
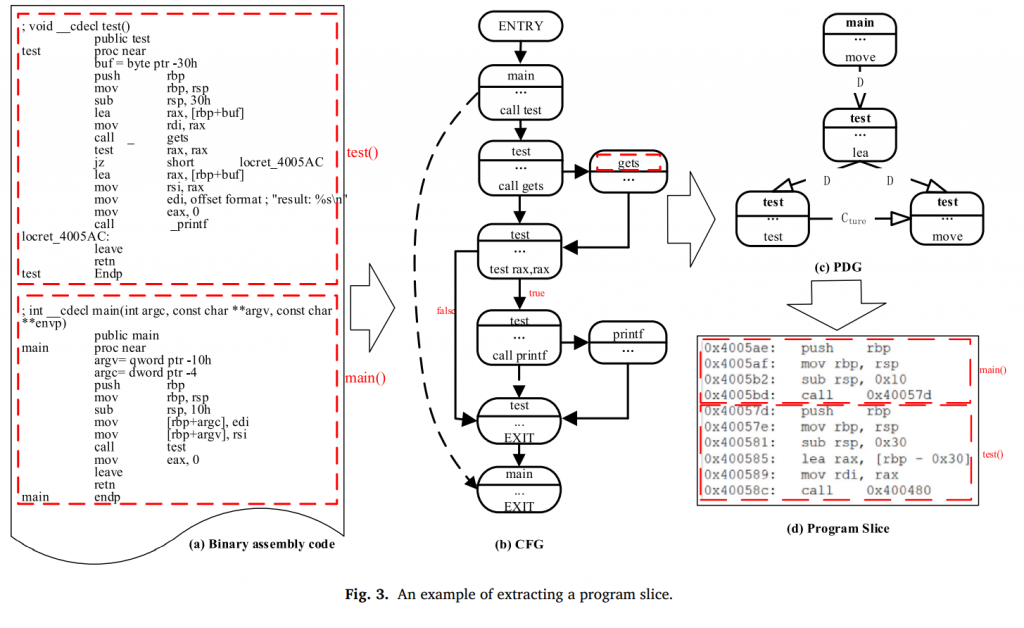
图3显示了从二进制程序中提取库函数 gets 的程序切片的过程。如图3(a)所示,程序包含两个函数,即主函数main()和用户定义的函数test()。图3(b)是二进制程序的控制流图。图3(c)是二进制程序的程序依赖图。箭头D表示数据依赖性,C表示控制依赖性。图3(d)展示了库函数调用 gets 的程序切片。
(1) 生成CFG和PDG。
CFG的构建依赖于对仿真程序执行和跟踪状态的分析。控制流中的每个基本块和基本块的顺序通过仿真执行的,这建立了CFG的边缘关系。PDG由两个函数之间的控制依赖性和数据依赖性构成。函数的数据流方向或控制流方向被视为一条边。
(2) 基于CFG提取库/API函数调用。
通过在CFG中查找库/API函数调用的函数名来访问函数原型节点。例如,在图3(b)中,虚线圆圈是库函数调用 gets 的函数原型节点。需要访问函数原型节点的前体,以获得函数调用的参数属性。
(3) 根据程序依赖关系图为每个库/API函数调用生成程序切片
使用符号执行技术和静态分析技术来分析二进制程序。首先,从参数所在的基本块的位置模拟程序的执行,然后向前和向后遍历二进制程序的控制流和数据流,以提取所有受影响的语句。这些语句包括程序在执行时传递的所有语句集。最后,这些语句组合起来形成库/API函数调用的程序切片。
通过比较汇编代码(图3(a))和程序切片(图3(d)),程序片包含主函数main中的语句,也包含用户自定义函数test中的语句。可以说明,提取的程序切片是跨函数的。
3.2.2 程序切片标记策略
每个程序切片都有一个相应的标签,表示该程序是否存在漏洞("1"对应程序切片中至少有一个漏洞,"0"则对应无漏洞)。具体标记过程如下:
首先从有已知漏洞的程序中获取相关的漏洞属性信息,包括漏洞名称、漏洞位置、CWE-ID等,并构建漏洞属性库。其次,遍历收集到的程序切片和漏洞属性库,以确定程序切片是否包含相应程序中的漏洞位置。
最后,为程序切片添加标签。该步骤可分为两部分:
(1) 如果正在搜索的程序切片包含任何漏洞,则将其标记为"1"。
(2) 如果在遍历程序切片和漏洞属性库之后,未发现程序切片包含任何漏洞,则将其标记为"0"。
3.3 程序切片转化为向量
首先,对程序切片进行分割,也就是说,用一个token来表示一个词。这样程序片就被转换成由一系列tokens组成的序列。
然后,使用得到的分词文本数据来训练词向量。考虑到上下文语义关系,使用词向量转换模型word2vec进行预训练。
最后,这些tokens被映射到固定长度,并且创建词汇词典,同时生成单词索引词典和单词向量词典。以这种方式,每个token可以通过索引字典中的索引来识别相应的词向量。
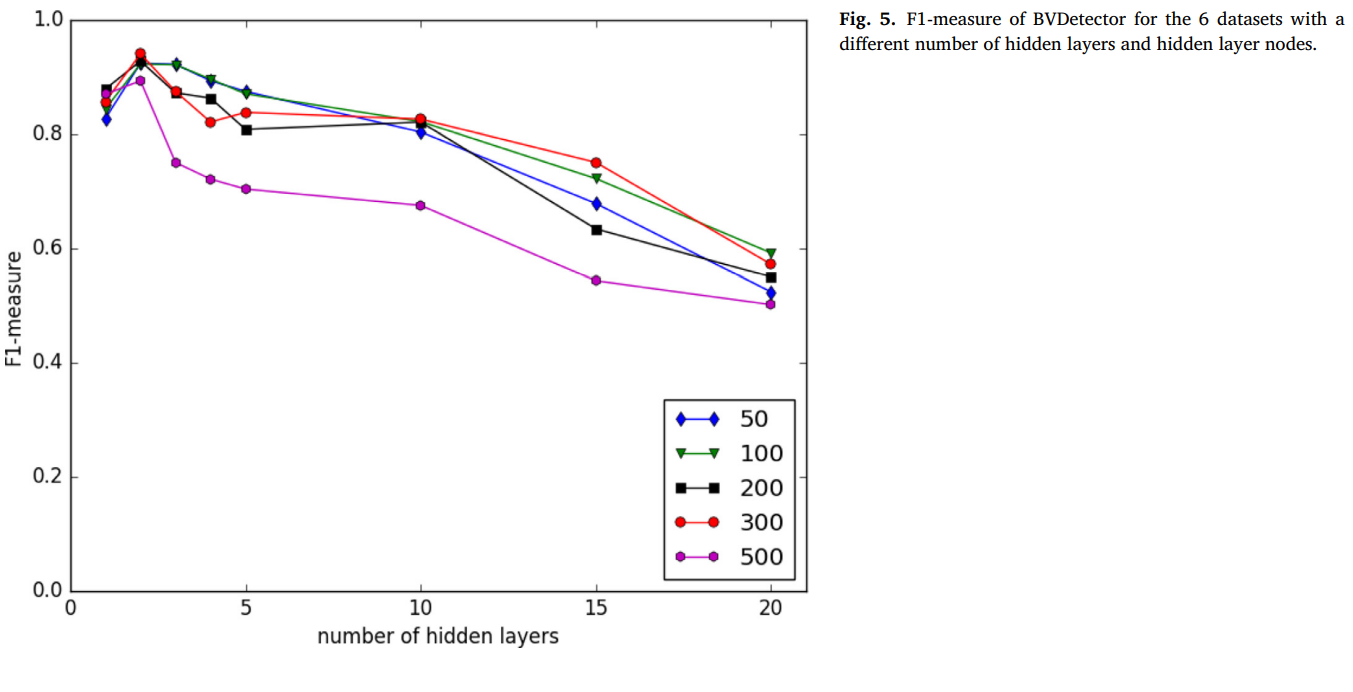
将所有词向量处理成同样的长度:假设 l 为深度神经网络的输入向量的长度,如果程序切片的向量长度小于 l ,则在向量末尾添加"0",直至其长度 = l 。如果程序切片的长度大于 l ,则删除一些语句。通过调整神经网络模型中隐藏层节点的数量,观察不同 l 值的设置对检测效果的影响,最后确定能达到最佳效果的 l 值。
4 实验准备
4.1 数据集
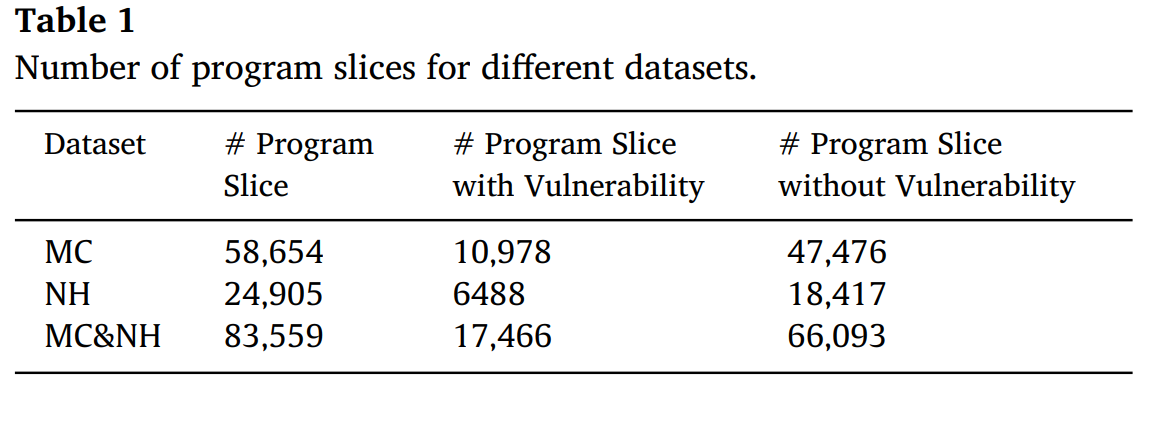
源代码程序采用SARD数据集,并将其编译为二进制程序,这些程序进一步分为训练程序数据集和测试程序数据集。最终收集了三种类型的数据集。
- 内存损坏(Memory Corruption, MC):该数据集中包含的程序漏洞与以意外方式对内存缓冲区执行操作的代码有关,从而导致预期程序控制流的滥用或损坏。MC包括缓冲区溢出和下溢、越界访问和内存安全错误。
- 数字处理(Number Handing, NH)。此数据集包含与数字处理弱点相关的程序。这些弱点包括:(a) 从一种数字数据类型转换为另一种数字类型所引起的问题。(b) 对数字数据执行数学运算所引起的问题。
- 内存损坏和数字处理(MC&NH):该数据集包含具有前两种类型漏洞的程序。
5 实验结果
5.1 评估指标
采用以下6个指标来评估实验结果:FPR(假阳率)、FNR(假阴率)、A(准确率)、P(精度)、R(召回率)、F1(F1值)。
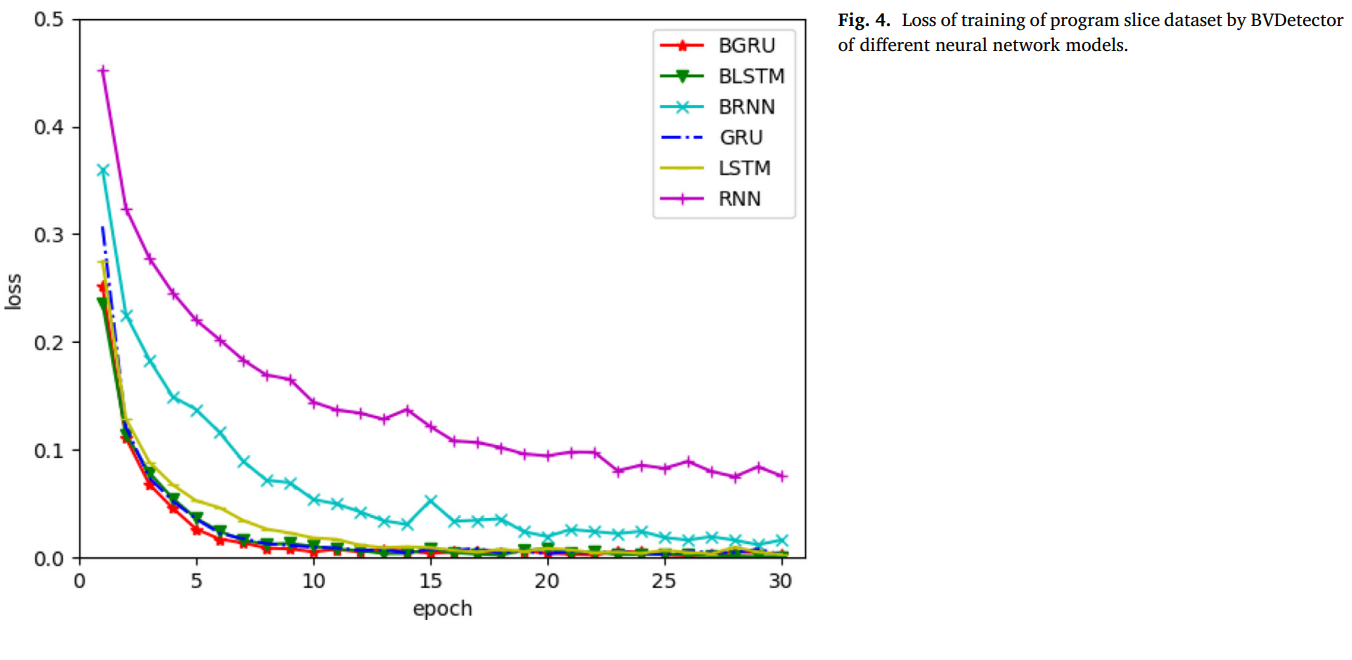
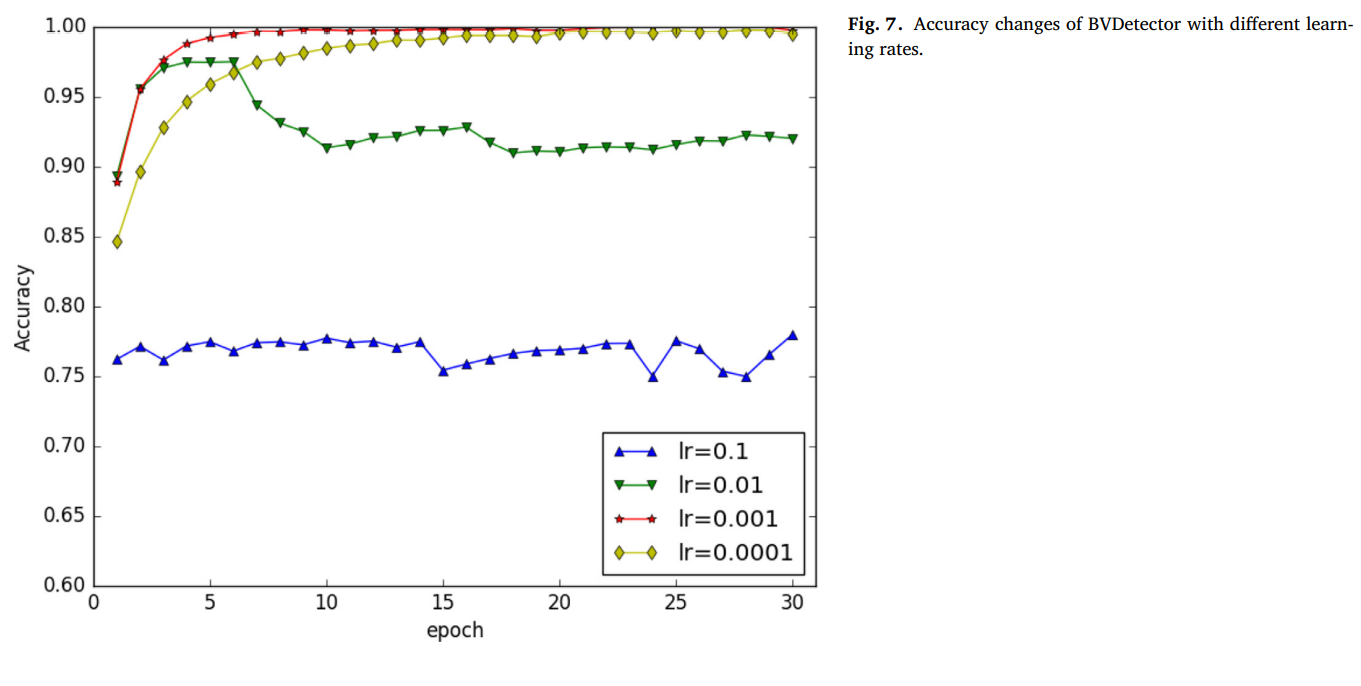
5.2 实验分析