
- A+
论文题目:VULOC: Vulnerability location framework based on assembly code slicing
论文出处:Journal of Systems and Software (JSS 25)
近期基于深度学习的代码漏洞检测取得了重大进展,然而它们在漏洞定位精度上仍存在一定的局限性。针对上述问题,作者提出了一种基于汇编代码切片的漏洞定位系统,可以实现漏洞sink点的精确定位。具体而言,它们通过gcc和gdb对源代码执行编译和反汇编,得到包含调试信息的汇编代码,然后对汇编代码进行函数级切片,最后构建漏洞汇聚/关注矩阵和BLSTM-LOC模型模拟漏洞汇聚过程(sink行精细切片),从而实现漏洞位置的精确定位。
1 背景动机
目前大部分基于深度学习的漏洞检测系统处于一个粗粒度水平,它们预测的漏洞范围通常为一个自定义函数或若干行代码切片,仍未真正实现精准输出漏洞行号,即输入程序P,输出漏洞行号L。同时源代码由于其复杂的语法结构,词汇表达以及隐匿的内存计算,在检测鲁棒性和训练效率上相对于汇编代码存在一定的局限性。

图1 源代码和汇编代码的比较
图1(a)展示了一个数组越界读取漏洞,图1(b)为其经过变量重命名后的变体,可以发现它们对应的汇编指令完全一致(如图1(e)所示),因为汇编代码通过寄存器运算,而寄存器的名字是固定的,与源代码数中数组名自定义不同。另外,在源代码中需要进一步计算 100*sizeof(int) 的值才能得到分配的内存空间大小 400(图1(d)),而汇编代码中的 400 已经被编译器提前算出。因此,相对于源代码,使用汇编代码进行漏洞检测存在以下几个优点:
- 通过汇编指令构建得到的token语料库更小,模型在Embedding阶段效率更高;
- 通过汇编代码训练得到的模型不受变量/函数重命名攻击的影响,漏洞检测鲁棒性更强;
- 分配的内存空间大小在源代码中是“隐式”的,而在汇编代码中是“显式”的,更利于检测与内存大小相关的漏洞,如缓冲区溢出,数组越界访问等,在细粒度检测上更具一定优势。
2 解决方案
作者在文中做出了如下几点贡献:
- 提出了一个新颖的细粒度漏洞定位框架VULOC,帮助开发人员快速定位漏洞sink行。
- 构建了一种包含源代码行号和汇编指令对应关系的代码切片结构。
- 提出了漏洞汇聚/关注矩阵和细粒度漏洞定位模型BLSTM-LOC,用于训练和预测。
- 在公开数据集上测试结果显示,准确率达到97.8%,平均定位距离小于1.0。
3 系统架构
文中的基本定义:
- ScFB:基于源代码切片的函数块。
- AcCB:基于汇编代码切片的代码块。
VULOC框架整体上分为3个部分:
- 编译和反汇编:将源代码编译为二进制文件,并利用GDB反汇编得到包含内存地址的汇编代码。
- 切片和标记:通过Addr2line将内存地址转化为源代码的行号,并基于源代码行号对汇编代码切片和打标。
- 训练和检测:将汇编代码切片和对应的标签作为模型的输入进行训练和漏洞预测。
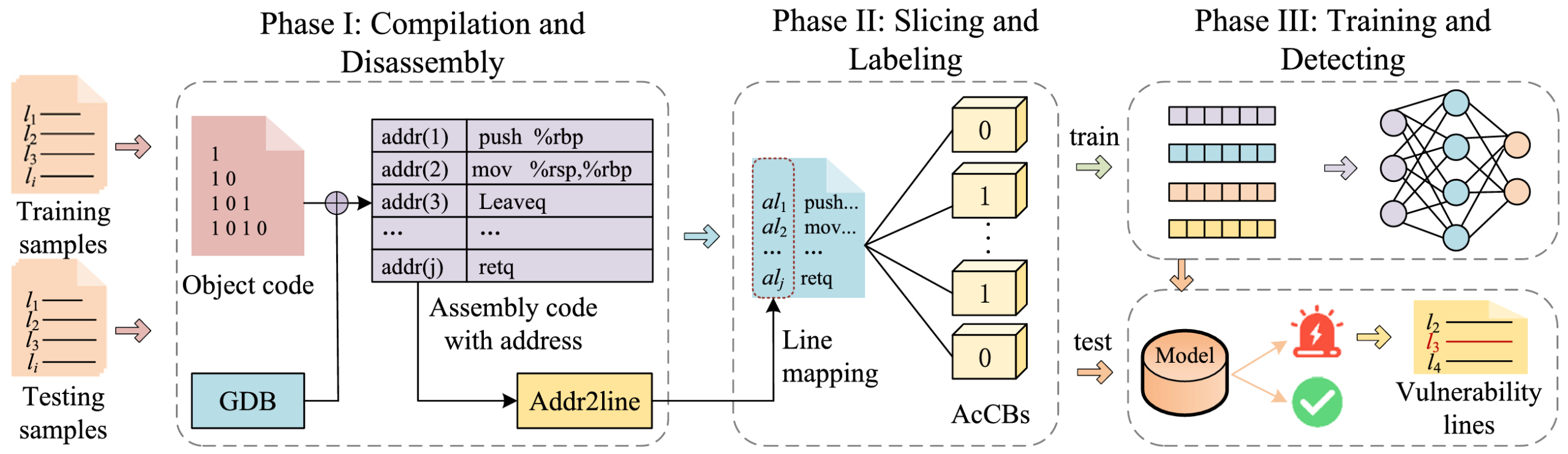
3.1 编译和反汇编
编译:为了保留源代码的结构,作者以最直接的方式为代码中定义的变量、函数和其他元素生成机器代码和汇编指令。这种方法有利于神经网络学习漏洞数据流,并模拟从源代码到sink的收敛过程。使用默认优化选项(在大多数 GCC 版本中通常为''-O0'')编译源代码。具体来说,使用“‘gcc -g -o source -I ./testcasesupport source.c’”命令将源代码“‘source.c’”编译为目标代码“‘source’”(包含所有训练和测试样本),其中“‘./testcasesupport’”表示头文件路径。
反汇编:在获取目标代码 “source ”后,执行 “gdb source”和 “disassemble”命令对目标代码进行反汇编,得到每个函数的 “地址:汇编指令 ”结构,如图 2(b) 所示。
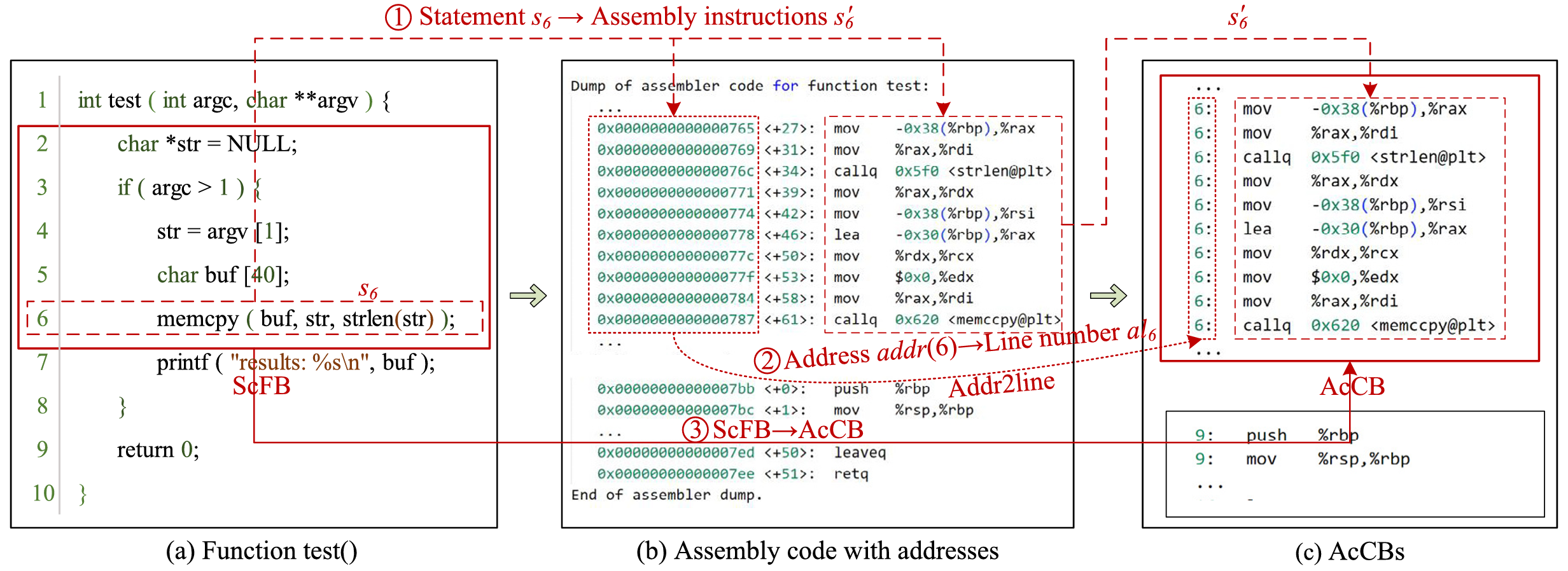
图 2 编译示例
3.2 切片和标记
汇编代码切片:在获得 “地址:汇编指令 ”结构后,遍历结构中的每个内存地址并使用 Addr2line 工具将地址转换为相应的源代码行号:执行 “addr2line address -e filepath -f -C -s ”命令,将内存地址转换为相应的源代码行号(其中 filepath 表示目标代码''source''的路径),从而得到''行号:汇编指令''的结构。例如,如图 2 中流程 2 所示,地址为 ''0×0000000000000765 - 0×0000000000000787''映射到图2(c)中的第6行。然后根据源代码的行号对汇编代码进行相应切片得到AcCB。
切片标记:根据以下原则对 AcCB 进行标注:查询数据集中提供的描述文件(即 manifest.xml 文件),如果 AcCB 包含已知漏洞,则标注为 “1”,反之则标注为 “0”。例如,假设AcCB 中汇编代码对应的源代码行号集表示为 𝐶𝑏 = {𝑎𝑙1,𝑎𝑙2,…,𝑎𝑙𝑛} (𝑎𝑙𝑛∈ 𝑙),假设 𝑣 为训练样本中的真实漏洞行号,如果 𝑣 ∈ cb,则AcCB被标记为 1,反之,AcCB被标记为0。
3.3 训练和检测
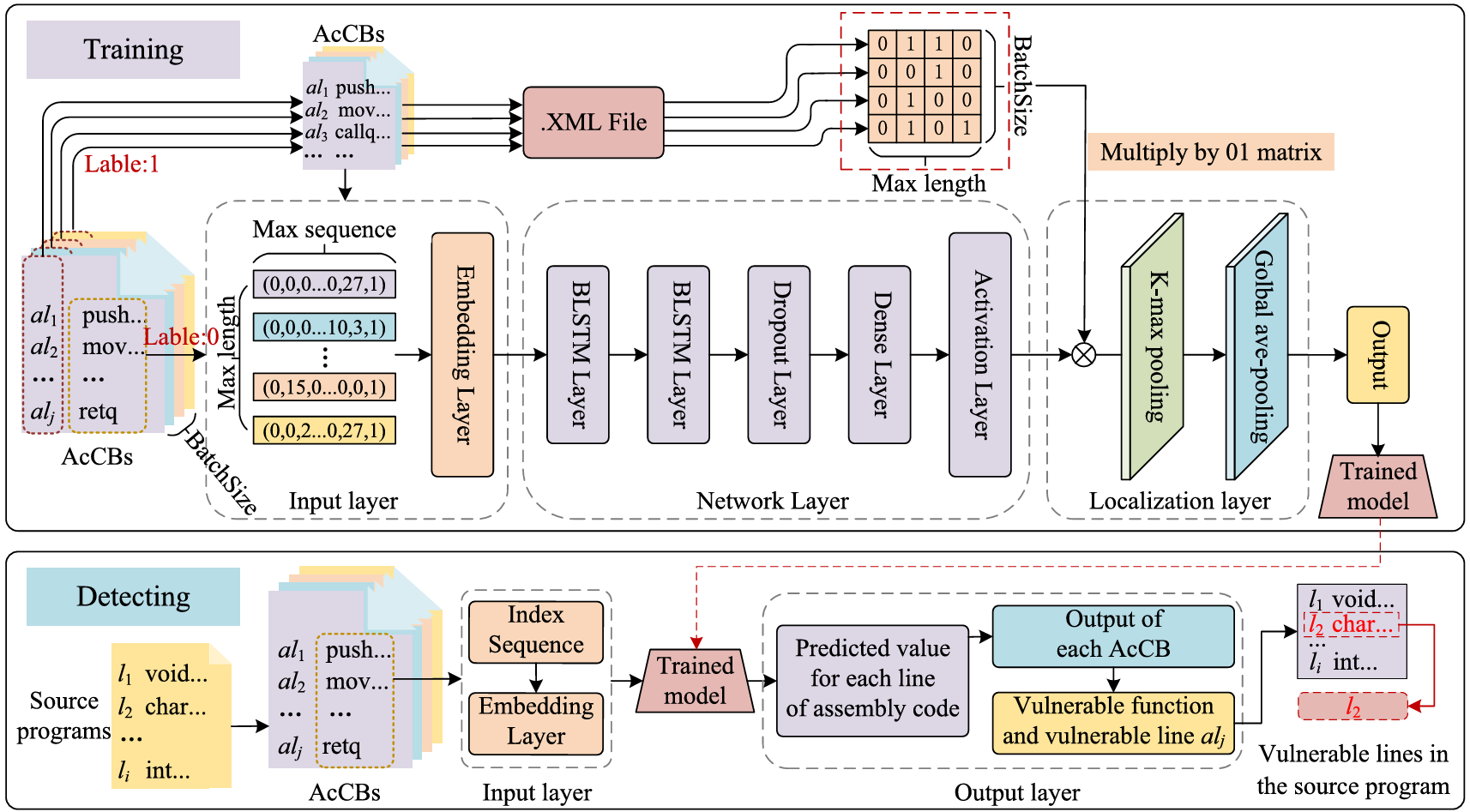
图 3 模型架构
3.3.1 模型构建
图 3 为VULOC的训练和检测流程,训练包含输入层、网络层和定位层三个部分,下面分别详细介绍:
输入层:每个标注的 AcCB 在输入神经网络之前都需要编码成一个向量。假设在 AcCB 中存在一段汇编代码“‘movq $0×0,-0×70 (%rbp)’”,根据分词方法(如 NLTK )将其处理成“movq’‘,”,’‘,“$0×0’‘,”,’‘,“,’‘,”-0×70’‘,’‘(’‘,’‘%rbp’‘,’‘)’”,并编码成每个向量。由于每个 AcCB 编码的向量长度不同,而神经网络需要固定长度的向量作为输入,因此需要统一长度。假设输入到神经网络的长度为 𝛿(即图 4 中的 “Max length”),如果向量长度小于 𝛿,在向量末尾填充 0;如果向量长度大于 𝛿,在向量末尾裁剪大于 𝛿的部分。
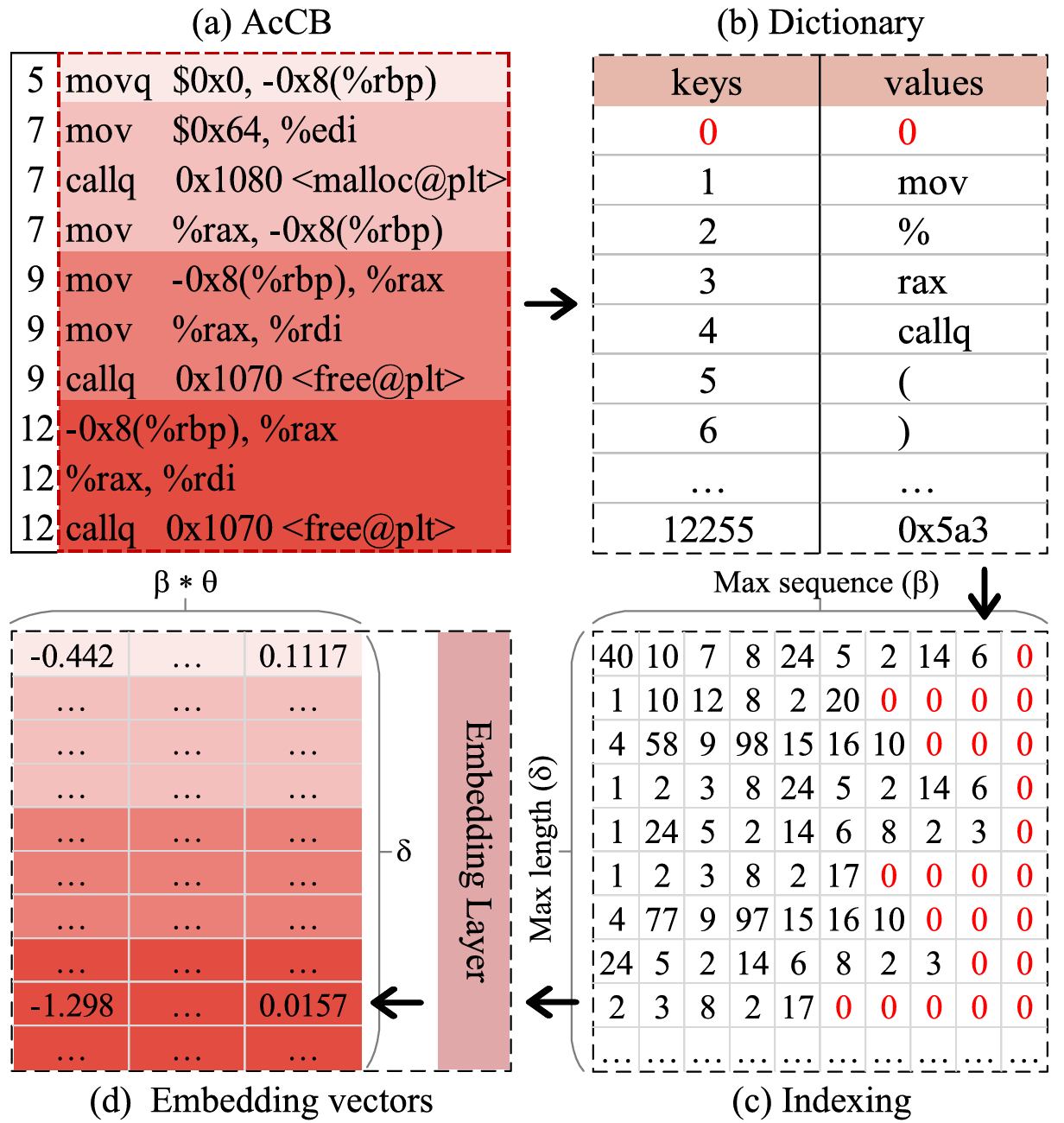
图 4 输入层结构
网络层:由两个BLSTM层神经网络、一个dropout层、一个Dense层和一个激活层组成。
定位层:如图5所示,在定位层中作者构建了一个漏洞关注/汇聚矩阵(文中称为01矩阵),该矩阵由汇编指令前的源代码行号和数据集说明文件Manifest.xml共同构建,用于在训练中模拟漏洞数据流汇聚过程和消除与漏洞sink点无关的冗余代码,这也是论文的主要工作之一。具体步骤为:获取一个MiniBatch中的所有AcCBs和它们包含的源代码行号,遍历每一个AcCB中的源代码行号和 Manifest.xml 文件中标注的关于该源程序(该AcCB所属的源代码)的真实漏洞行(即Ground Truth),如果AcCB中的源代码行号为真实漏洞行,则在01矩阵对应位置设为 1,不包含漏洞行则在对应位置设为 0。对于MiniBatch中的所有AcCB都执行同样的操作,最终得到一个大小为 N x 𝛿 的 01矩阵。
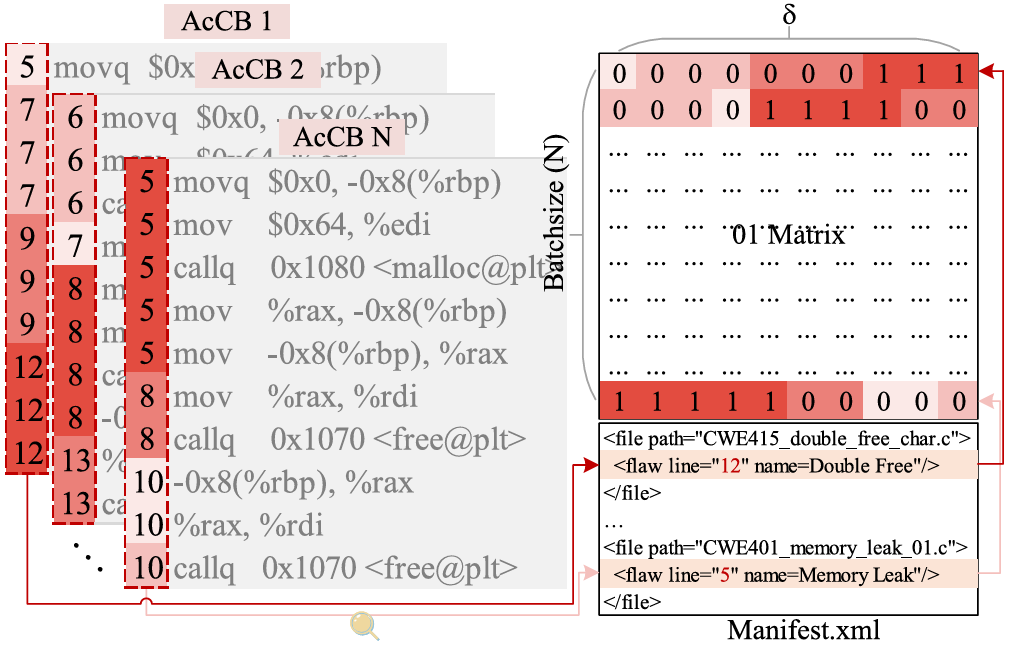
图 5 构建 01 矩阵
在01矩阵构建完成后,将其与网络层的输出相乘,消除与漏洞sink点无关的代码,并将得到的值输入到后续的K-max池化层和全局平均最大池化层中,用于确定漏洞函数和预测漏洞行号。
3.3.2 训练检测
模型训练:首先,编译数据集中的所有源程序,并生成带标签的 AcCB。然后输入这些 AcCB 及其相应的标签来训练模型。对于易受攻击的 AcCB(图 3 中标记为 “1”),提取行号并生成相应的 01 矩阵。在将 AcCB 中的汇编指令送至输入层,并嵌入为向量矩阵,作为 BLSTM 模型的漏洞特征输入。输出通过失活层、密集层和激活层获得。然后,输出与 01 矩阵相乘,所得值被送入 k 最大池化层和全局平均池化层,以选择最大平均值。对于不包含漏洞的 AcCB(图 3 中标注为 “0”),不生成 01 矩阵,而是直接将其输入模型以获得输出值。计算每个输出值与相应标签的交叉熵损失,并在训练过程中通过反向传播利用该损失更新网络模型。最终,得到一个用于漏洞检测和定位的深度学习模型 BLSTM-LOC。
漏洞检测:将测试集中的每个 AcCB 编码为长度为 𝛿 × 𝜃 × 𝛽 = 60,000 的向量,其中 𝛿、𝜃 和 𝛽 的值分别为 120、50 和 10,即每个token被编码为长度为 50 的向量,每行的最大汇编指令数(tokens)为 10。 如图 3 检测部分所示,检测模型以源程序为输入,生成与这些源程序相对应的 AcCB,将每个 AcCB 编码的向量输入训练模型,得到每行汇编代码的预测值。当 AcCB 中所有汇编代码行的平均预测值大于阈值𝜆(设为 0.5)时,模型判定该 AcCB 中包含漏洞,并输出预测值最大的行 𝑙𝑗,最终得到源程序的漏洞行。AcCB 中的行号𝑎𝑙𝑗 只用于在输出阶段映射源代码的漏洞位置,而不会作为参数输入到网络模型进行漏洞预测。因此,漏洞检测步骤不需要"‘XML’'文件的参与(检测时无须生成 01 矩阵)。图 5 为 AcCB 对应的输出示例,''Value''表示每一行汇编指令的预测值,范围从 0 到 1.0,越接近 1.0 表示存在漏洞的可能性越大;''Ground truth''表示语句的真实标签,其中''1''表示存在漏洞,''0''表示不存在漏洞。将预测值大于 0.5 的语句确定为漏洞语句,即源程序中的漏洞行是第 6 行。
4 实验分析
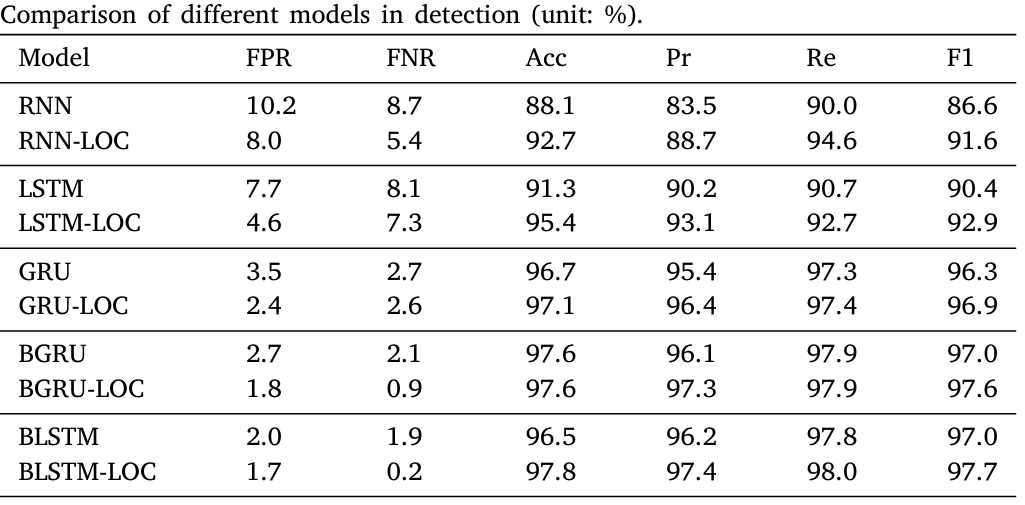
1. 定位层是否能提升漏洞检测性能?(RQ1)分析:
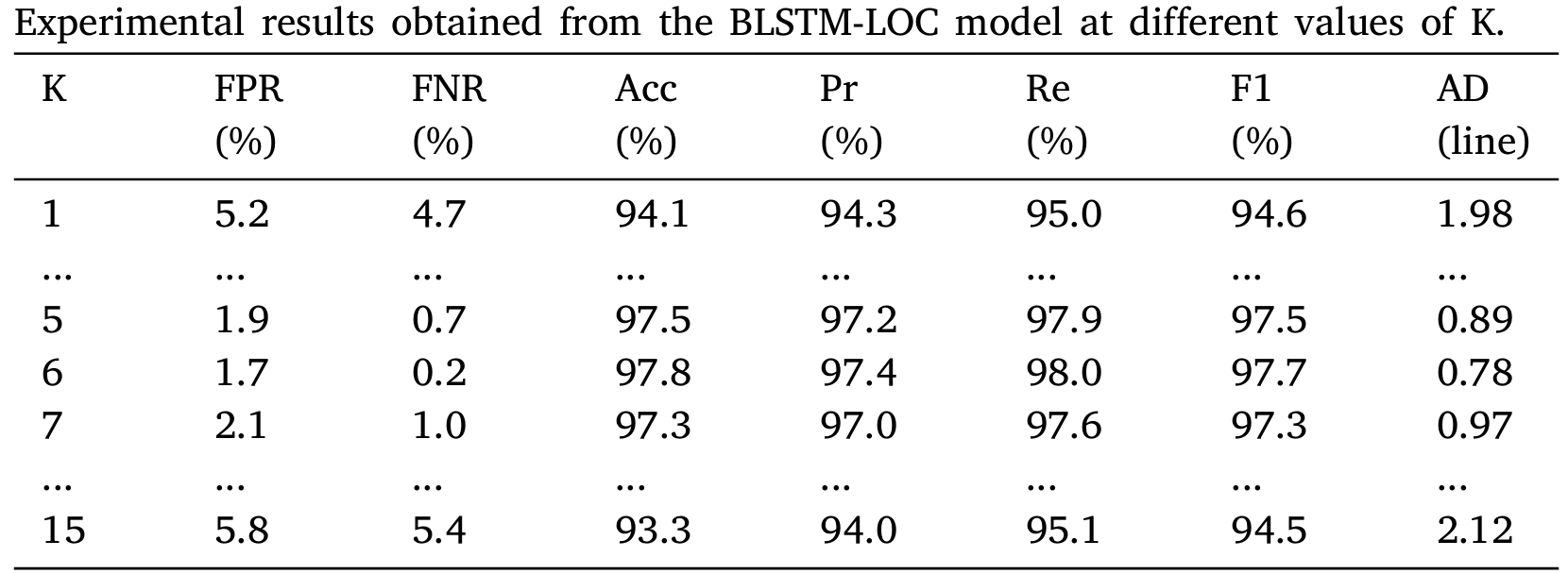
2. 在K-max池化中最优K值是什么?(RQ2)分析:
3. 基于汇编代码的漏洞检测是否比基于源代码的更好?(RQ3)分析:

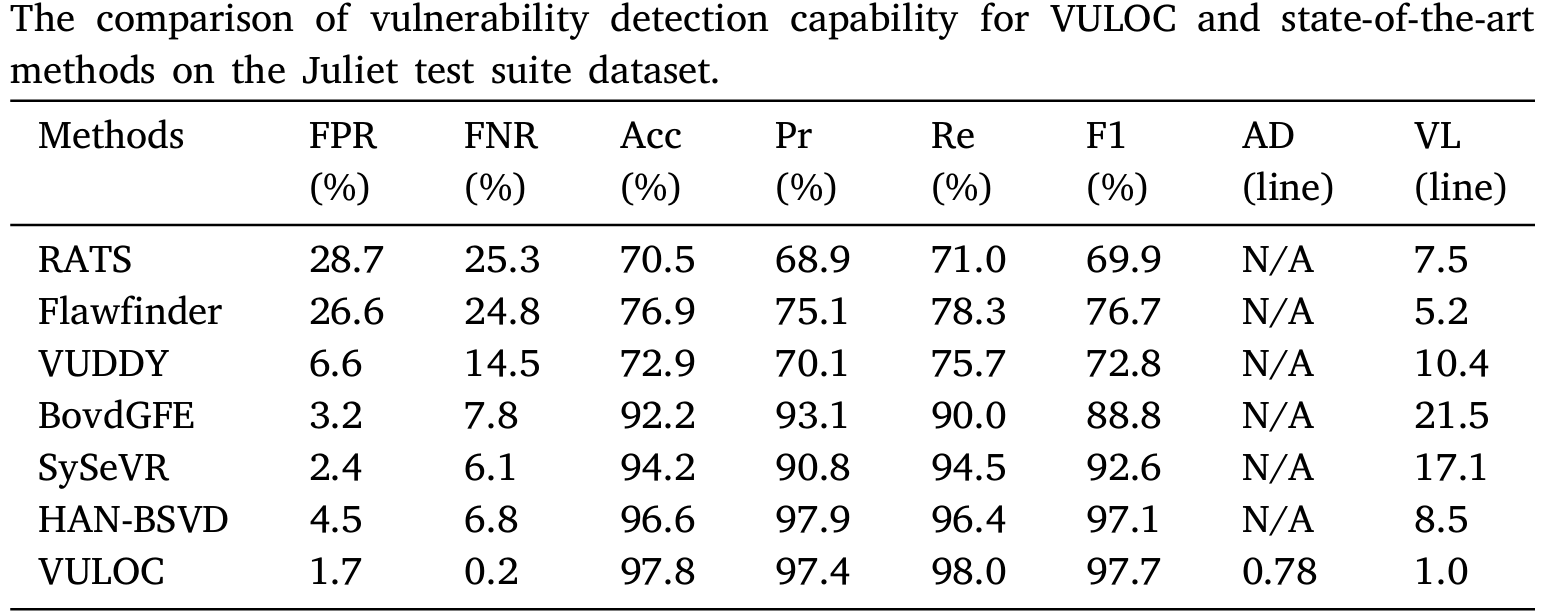
4. 与SOTA漏洞检测方法相比,VULOC性能如何?(RQ4)分析:
5. VULOC在真实场景中的检测效果如何?(RQ5)分析:
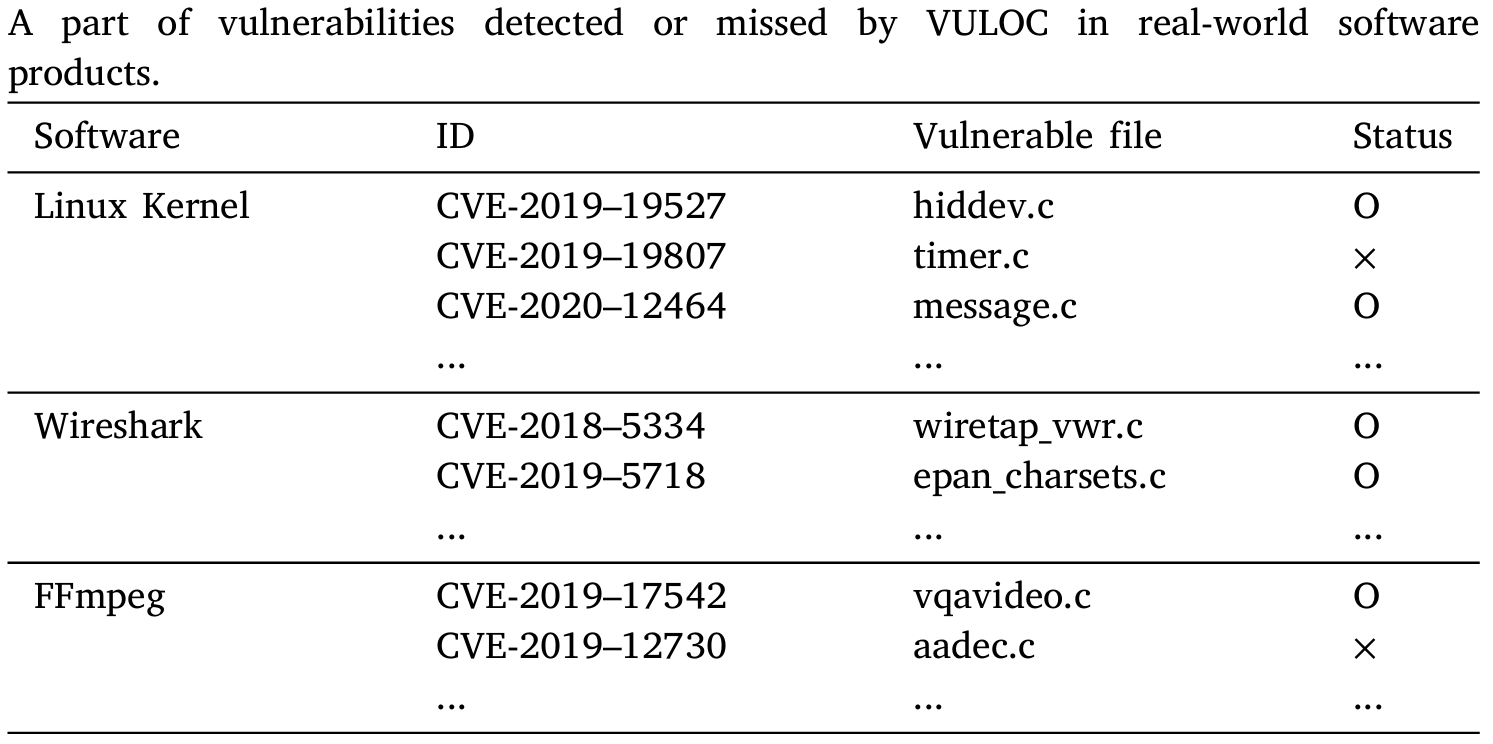
5 总结展望
全文总结:论文提出了一种基于汇编代码切片的漏洞定位系统,它能有效、高精度地检测 C/C++ 程序中的漏洞。VULOC 通过汇编代码切片技术,利用汇编代码和源代码行号之间的映射关系以及所提出的 BLSTM-LOC 模型,提高了漏洞检测的粒度和准确性。实验表明,VULOC 在两个公共数据集上都表现出了卓越的性能,并且在真实世界的软件产品中依然有效,这为检测漏洞提供了一种全新而强大的方法。
未来展望:提出的方法具有下列局限性:(i) 仅适用于 C/C++ 源程序的漏洞检测,不能用于其他编程语言;(ii) 要求将源程序编译成汇编代码,因此目标程序必须编译成功,编译失败的程序无法检测;(iii) VULOC 无法检测那些跨函数调用引起的漏洞。(iv) VULOC 要求训练数据集标注漏洞位置,否则无法进行模型训练。(v) 将VULOC应用于其他系统架构时,需要重新训练神经网络。(vi) 不同的编译器版本或优化级别可能会导致生成的汇编代码出现显著差异(例如,O2 和 O3 等优化选项可能会改变代码结构和代码执行顺序。代码结构和内存操作的执行顺序),因此需相应地重新训练神经网络模型。
