
- A+

GNN已被证实能有效学习源代码的图表示,然而GNN难以处理代码结构图中长距离节点之间连接的局限性,导致无法捕获代码图的全局信息(即远距离节点间的依赖关系)。针对上述问题,提出漏洞检测框架AMPLE,它包括图简化(缩小代码结构图的节点大小来减少节点之间的距离)和增强图表征学习(捕捉远处图节点之间的关系)两个部分。在三个公共基准数据集上的实验表明,AMPLE 的准确率和 F1 分数指标分别比最先进的方法高出 0.39%-35.32% 和 7.64%-199.81% ,证明了 AMPLE 在学习代码图的全局信息以进行漏洞检测方面的有效性。
1 问题描述
GNN 模型在处理非直接相邻节点之间的长距离连接时存在局限性。虽然可以使用多层堆叠的 GNN 来学习图的全局信息(即节点间的长距离依赖关系),但深度 GNN 产生的过度平滑问题会导致具有不同标签的节点出现相似的嵌入,从而降低漏洞检测性能。现有的 GNN 模型(如 GGNN、GCN)无法充分模拟图中的边特征。
2 解决方案
提出了一种新型漏洞检测框架 AMPLE,它具有图形简化和增强型图形重现学习功能。AMPLE 包括两大部分:1)图形简化,通过缩小代码结构图的大小来减少节点之间的距离。2) 增强图形表示学习,包括两个模块。边缘感知图神经网络模块考虑边缘类型信息,并将异构边缘信息融合到节点表示中;而核缩放表示模块则扩大卷积核大小,以明确捕捉远距离图节点之间的关系。
3 框架设计
AMPLE由两个部分组成:图简化模块、增强图表征学习。
3.1 图简化
1)基于类型的图简化:类型合并规则如表 1 所示,PType表示父节点类型,CType表示子节点类型。合并规则1,2,3,4,5-7分别对应 C/C++ 编程语言中不同类型的语句,包括表达式语句、标识符声明语句、条件语句、for-loop 语句和函数调用语句。对于每一对与合并规则相匹配的相邻节点,其子节点将被删除,因为其信息是对父节点的细化,也可以反映在其后续节点中。
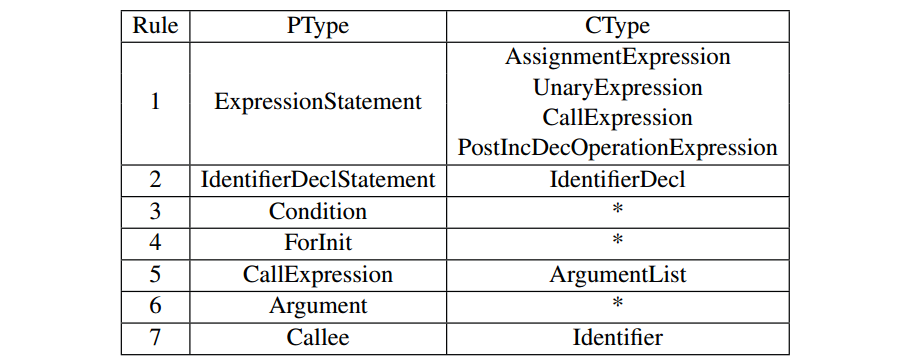
表 1 类型合并规则表
如图 1 所示,红色虚线边框的节点根据规则 2 与父节点合并。具体来说,子节点 " * first = malloc(10) "中的信息也被父节点及其三个子节点所覆盖。
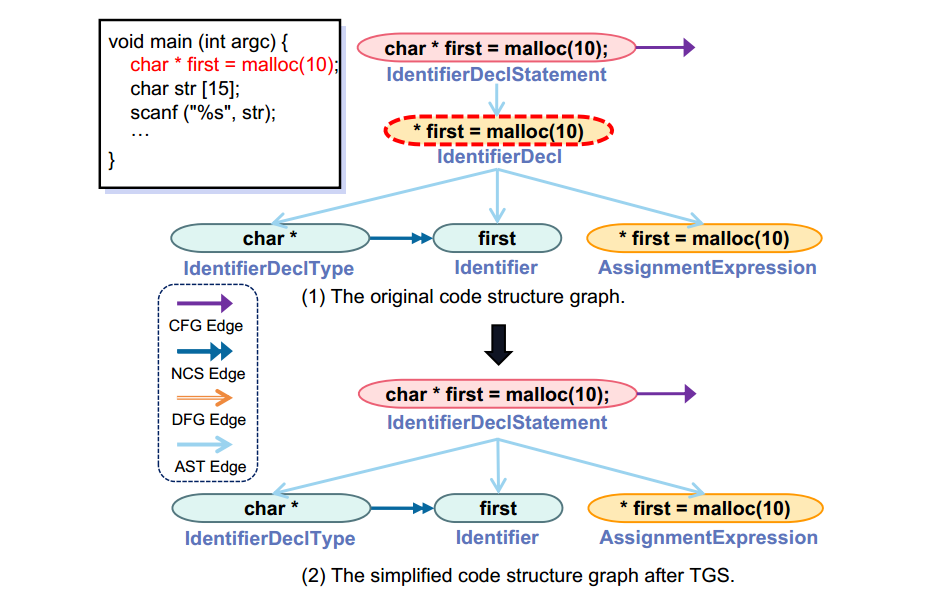
图 1 基于节点类型的图简化
2)基于变量的图简化:在代码结构图中将具有重复变量的节点合并为一个节点,仅适用于AST的叶节点,因为叶节点不具有子节点,将它们合并不会改变父子层次结构。合并后的变量节点有多个父节点,因此可以同时聚合来自不同语句的信息,可以增强节点表示,促进全局图表征学习。图 2 展示了一个基于变量的图简化实例。变量 "str "同时出现在 "char str[15]; "和 "scanf("%s",str); "的子节点中,因此合并了这两个 "str "叶节点。
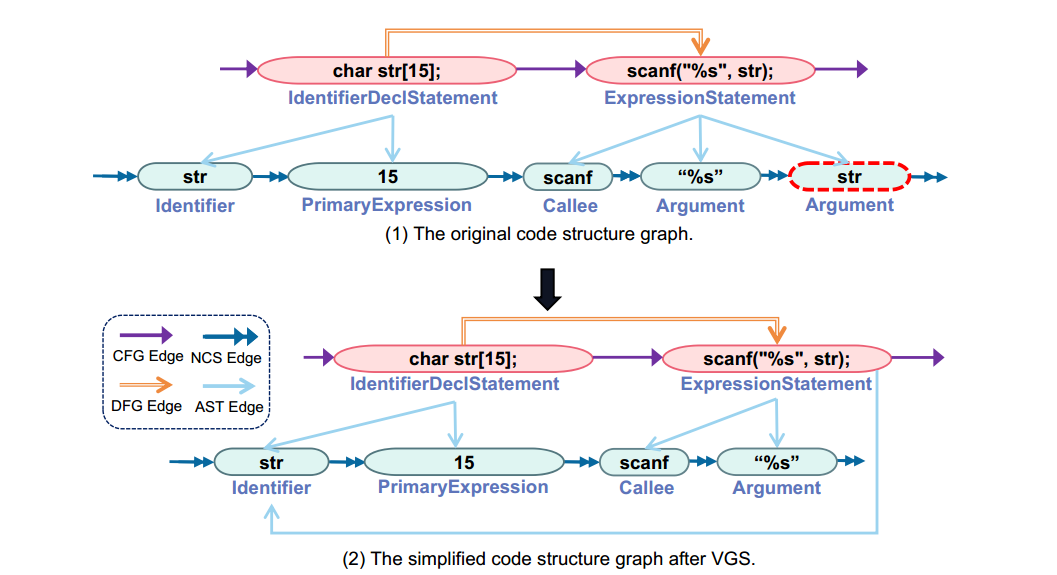
图 2 基于变量的图简化
图简化算法如算法1所示:整个图形简化(GS)过程如算法 1 所示,其中类型图简化(TGS)和变量图简化(VGS)分别对应第 2-19 行和第 20-25 行。该算法以原始代码结构图为输入,根据 TGS 和 VGS 输出简化后的代码结构图。对于 TGS,算法对 AST 执行广度优先遍历,每次遇到一对符合表 1 中合并规则的相邻节点(u、v)时(第 10 行),都会执行以下操作(第 11-12 行):删除 v 和与 v 相连的边,然后在 u 和 v 的所有子节点之间添加新边。对于 VGS,该算法首先获取所有包含相同变量的组,然后将包含相同变量的节点合并为一个节点。最终简化后的代码结构图被输入到 AMPLE 的后续部分。

算法 1 图简化算法
3.2 增强图表征学习
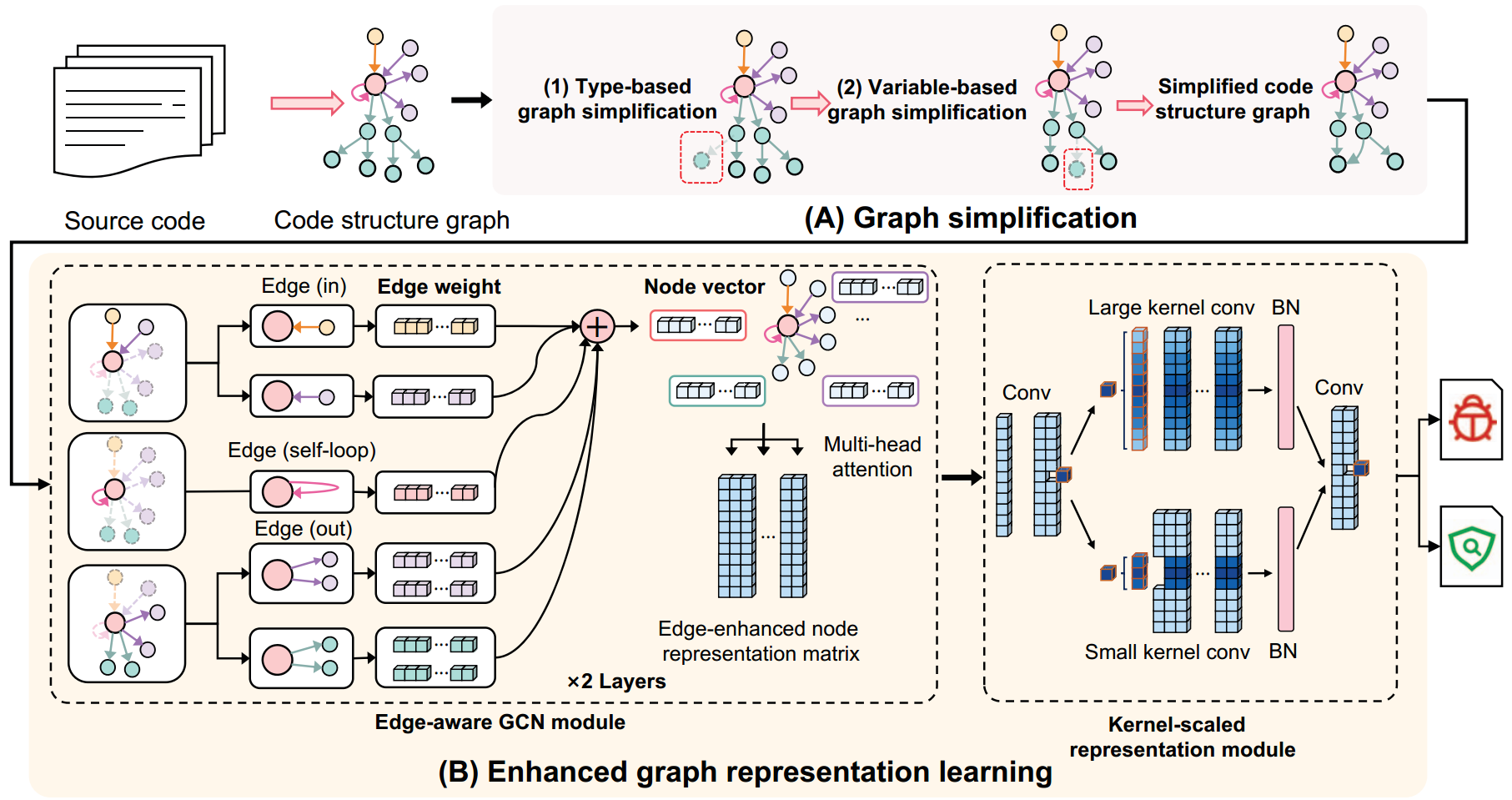
图 3 AMPLE检测架构
图 3(B)为增强图表征学习模块,该模块主要进行图节点嵌入以及下游分类任务,由边缘感知图卷积网络模块和核缩放表征模块两部分组成。
1)边缘感知图卷积网络模块(Edge-aware GCN module,EA-GCN):简化后的代码结构图有3种类型的边,分别为进入边(in),出去边(out)和自循环边(self-loop),这些边也即代码结构图中的 CFG Edge、NCS Edge,DFG Edge 或 AST Edge。EA-GCN 模块首先通过对三种不同类型的边分别进行加权(不同类型的边对于节点的重要程度不同,这里的边缘感知(EA)可以理解为在图结构中嵌入了 3 种分别表示不同语法和语义信息的边(Edge),利于每个节点聚合邻近节点更多以及更强的语义信息),然后聚合邻近节点来计算目标节点向量(实际上就是对与目标节点相邻的节点嵌入表示),在图中的每个节点重复执行此操作,得到所有的节点向量,最后根据多头注意力增强重要节点的表示,得到边增强的节点表征向量矩阵。
2)核缩放表征模块:该模块旨在通过明确捕捉远处节点之间的关系来学习图的全局信息。在得到边增强的节点表征向量矩阵后,在核缩放表征模块中设计两个不同尺寸的卷积核,一个大核,和一个小核。大核用于捕获边缘/远处节点特征,小核侧重于邻近/邻居节点特征的获取,通过上述操作,从而捕获代码结构图的全局信息。
4 实验分析
4.1 数据集
AMPLE 在研究中采用了三个漏洞数据集,包括 FFMPeg+Qemu、Reveal和 Fan et al。实验数据集的统计数据如表 2 所示。Devign 提供的 FFMPeg+Qemu 数据集是人工标注的,来自两个开源 C 项目,它包含约 1 万个易受攻击实例和 1.2 万个非易受攻击实例。Reveal 数据集收集自两个开源项目:Linux Debian 内核和 Chromium。该数据集包含约 2k 个易受攻击实例和 20k 个非易受攻击实例。Fan 等人从 300 多个开源 C/C++ GitHub 项目中收集了数据,涵盖了 2002 年至 2019 年通用漏洞与暴露(CVE)数据库中的 91 种不同漏洞类型,该数据集包含约 1 万个易受攻击实例和 17.7 万个非易受攻击实例。
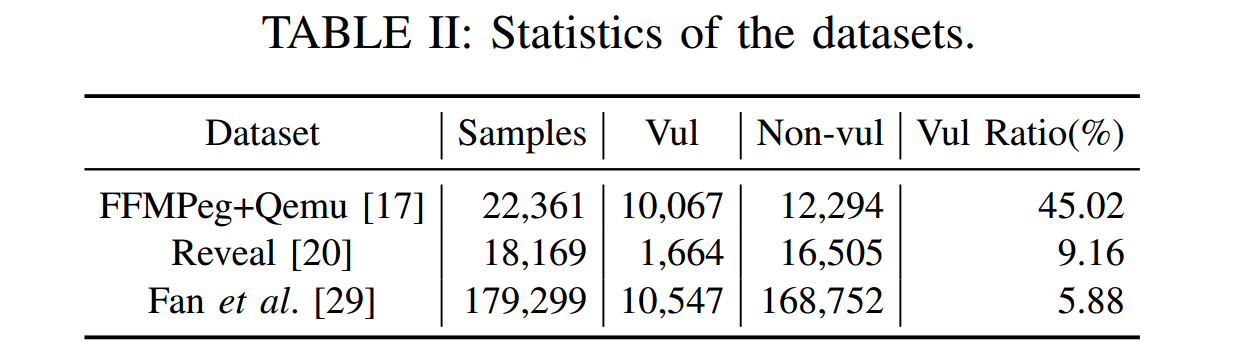
表 2 数据集
4.2 结果分析
文中采用以下 4 个指标:Precision、Recall、F1 score、和Accuracy来衡量实验结果。
AMPLE根据下列4个问题来展开实验:
- 问题 1:AMPLE 在漏洞检测方面的效果如何?
- 问题 2:图形简化是否提高 AMPLE 的性能?
- 问题 3:增强图形表征学习是否提高 AMPLE 的性能?
- 问题 4:超参数对 AMPLE 性能有何影响?
针对问题 1,如表 3 所示,就准确率和 F1 分数而言,AMPLE 优于所有基准方法。特别是,在三个数据集上,AMPLE 的 F1 分数比最佳基准方法分别提高了 7.63%、16.48% 和 40.40%。
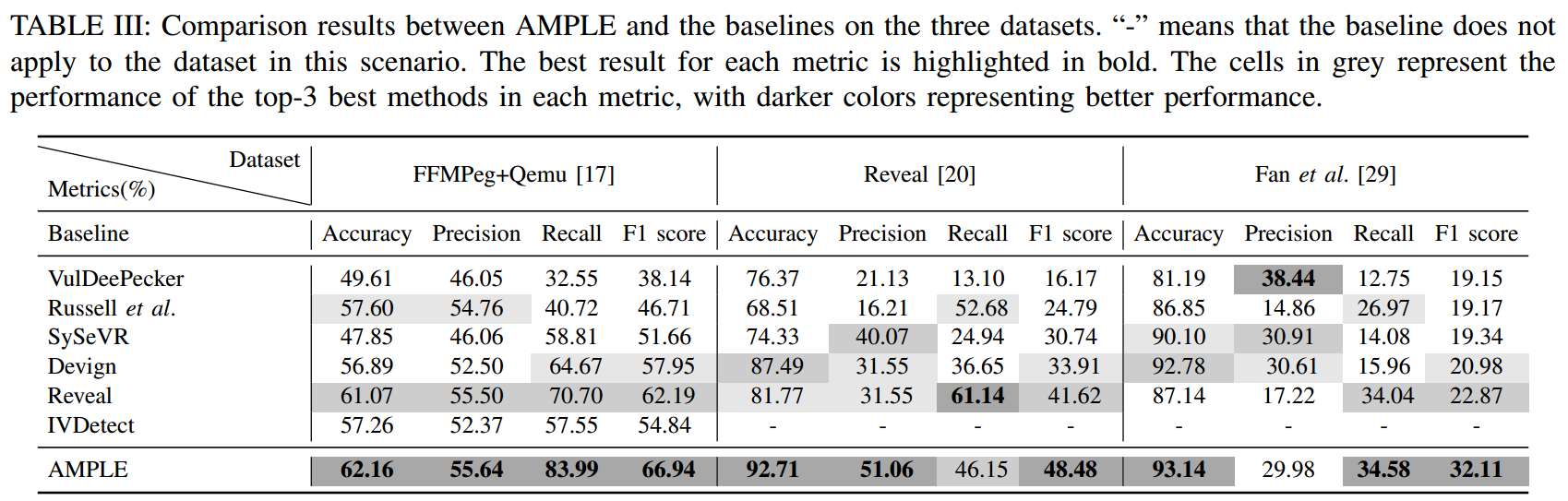
表 3 与基线和SOTA方法对比实验结果
针对问题 2,如表 4 所示,可以观察到图简化对 AMPLE 的性能有显著贡献,在三个数据集上的 F1 分数分别提高了 12.56%、14.20% 和 34.86%。节点、边和距离的平均简化率分别为 41.64%、16.79% 和 41.65%。
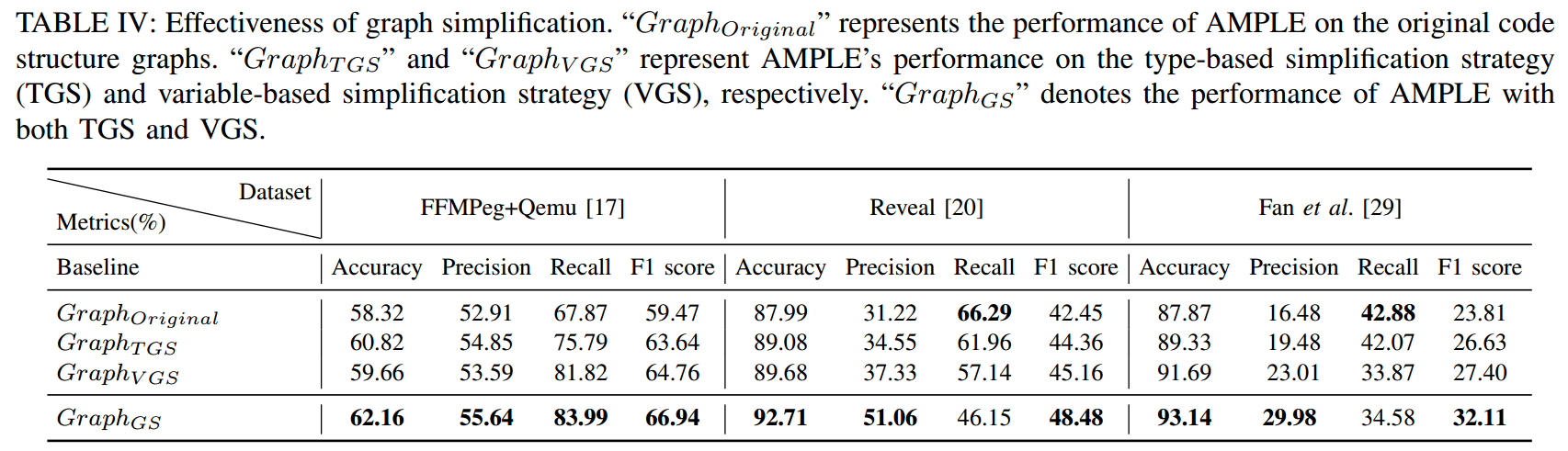
表 4 图简化前和简化后的实验结果对比
针对问题 3,如表 5 和表 6 所示,增强图表征学习模块可以有效提高 AMPLE 性能。在 FFMPeg+Qemu、Reveal 和 Fan 等数据集的测试中,EA-GCN 模块分别提高了 4.46%、30.08% 和 48.66% 的 F1 分数,而 KSR 模块则分别提高了 13.13%、57.53% 和 27.93%。
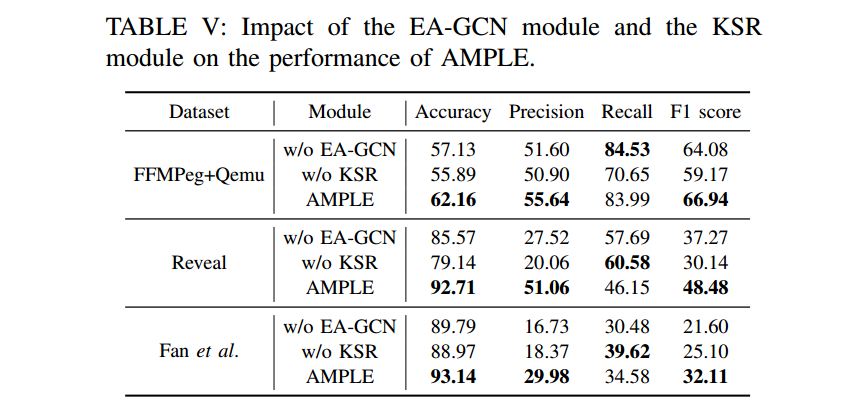
表 5 EA-GCN 模块核 KSR 模块对 AMPLE 性能的影响
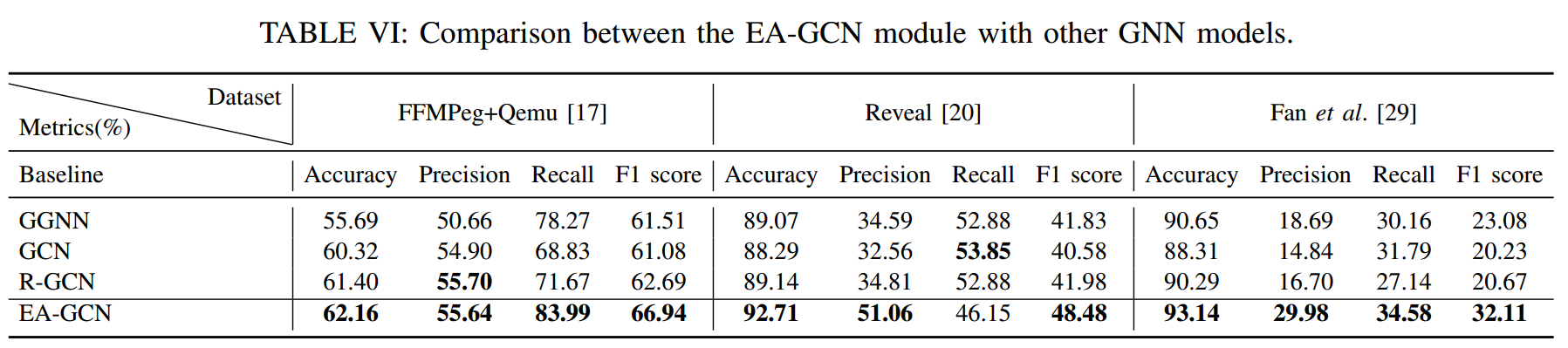
表 6 EA-GCN 与其它 GNN 模型的实验结果对比
针对问题 4,如表 7 所示,不同的超参数设置会影响 AMPLE 在漏洞检测中的性能。
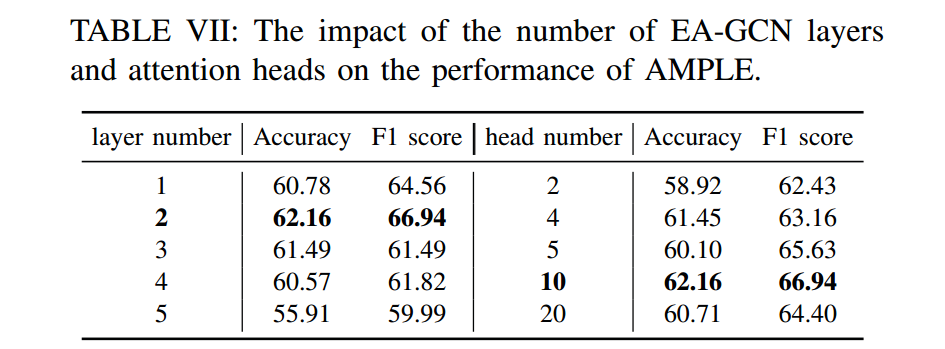
表 7 超参数对 AMPLE 性能的影响
5 总结
文中提出了一种新颖的漏洞检测框架 AMPLE,它具有图简化和增强图表征学习功能。AMPLE 可以缩小代码结构图的节点数量,从而减少节点之间的距离。同时结合边缘类型来增强局部节点的表示,以应对节点表示中更多的异构关系。通过捕捉远处图节点之间的关系来获取图的全局信息。与最先进的基于深度学习的方法相比,AMPLE 在所有数据集上的漏洞检测性能都有显著提高,F1 分数提高了 7.64%-199.81%。
6 原文链接
论文题目:Vulnerability Detection with Graph Simplification and Enhanced Graph Representation Learning
论文出处:2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE 2023)
