
- A+
这篇文章提出了一种可以同时实现高检测能力和高定位精度的漏洞检测器VulDeeLocator。主要包含两个创新:1)利用中间代码来容纳额外的语义信息。2)使用粒度细化的概念来确定漏洞的位置。当应用于从三个真实世界软件产品中随机选择的200个文件时,VulDeeLocator检测到18个已确认的漏洞,其中16个为已知漏洞,另外两个未在NVD中报告,但已被Libav供应商静默修补。

1 提出问题
漏洞是造成网络攻击的主要原因,理想的漏洞检测应同时具备高检测能力和高定位精度(即定位漏洞代码所在的行号)。
目前的静态分析方法主要分为基于代码相似性的检测和基于模式的检测,它们存在以下缺陷:
- 基于代码相似性的检测可以检测由代码克隆导致的漏洞,并实现高定位精度,当用于检测不是由代码克隆引起的漏洞时,会产生较高的假阴性(即检测能力很低)。
- 基于模式的检测进一步分为基于规则的检测和基于机器学习的检测。基于规则的检测可以识别出漏洞代码行,但存在高假阳率和高假阴率,且需要人工定义检测规则。基于机器学习的检测无法实现高定位精度,因为它们的检测细粒度通常在函数级别。
- 目前使用深度学习在程序切片级别检测的方法虽然解决了手动定义特征的问题,但检测能力和定位精度仍然不足。如SySeVR公布的数据集中,78.8%的程序切片有10行代码,47.8%的程序切片有20行代码,这说明定位精度较低。
目前最先进的方法,1)无法捕捉跨程序文件的语义相关语句之间的关系,因为程序通常包含许多用户定义的和系统头文件(如.h),用于指定类型和宏指令,不能通过单独分析每个源代码文件来实现,因为这些类型和宏指令是在程序文件(如.c)中使用,而在头文件中定义的,这就要求进行跨文件的依赖性分析。2)无法容纳准确的控制流和变量定义使用关系,这是由于每个变量没有被精确地分配一次并且基于源代码的表示具有许多构造(例如标识符)。
2 解决方案
文章提出一种基于深度学习的漏洞检测器VulDeeLocator,用于C程序源代码漏洞检测。与最先进的探测器相比,VulDeeLocator在F1值、假阳率和假阴率分别平均提高了9.8%,7.9%,和8.2%,以及漏洞定位精度提高了4.2倍。
2.1 文章贡献
- 通过定义关系链接多个文件,并利用基于中间代码的表示来解决上述基于深度学习的漏洞检测器检测能力不足的问题。因为基于中间代码的表示采用静态单赋值(SSA)形式,因此可以确保每个变量都被定义并使用,并被精确赋值一次。
- 提出粒度细化的概念来定位漏洞代码行号。构建了用于漏洞检测和定位的BRNN-vdl模型,将VulDeeLocator的漏洞输出精确至大约3行代码。
- 提供了基于LLVM中间代码的数据集,包含157692个漏洞候选,其中40450个存在漏洞,117242个不存在漏洞。提供了VulDeeLocator的源代码:https://github.com/VulDeeLocator/VulDeeLocator
3 方法介绍
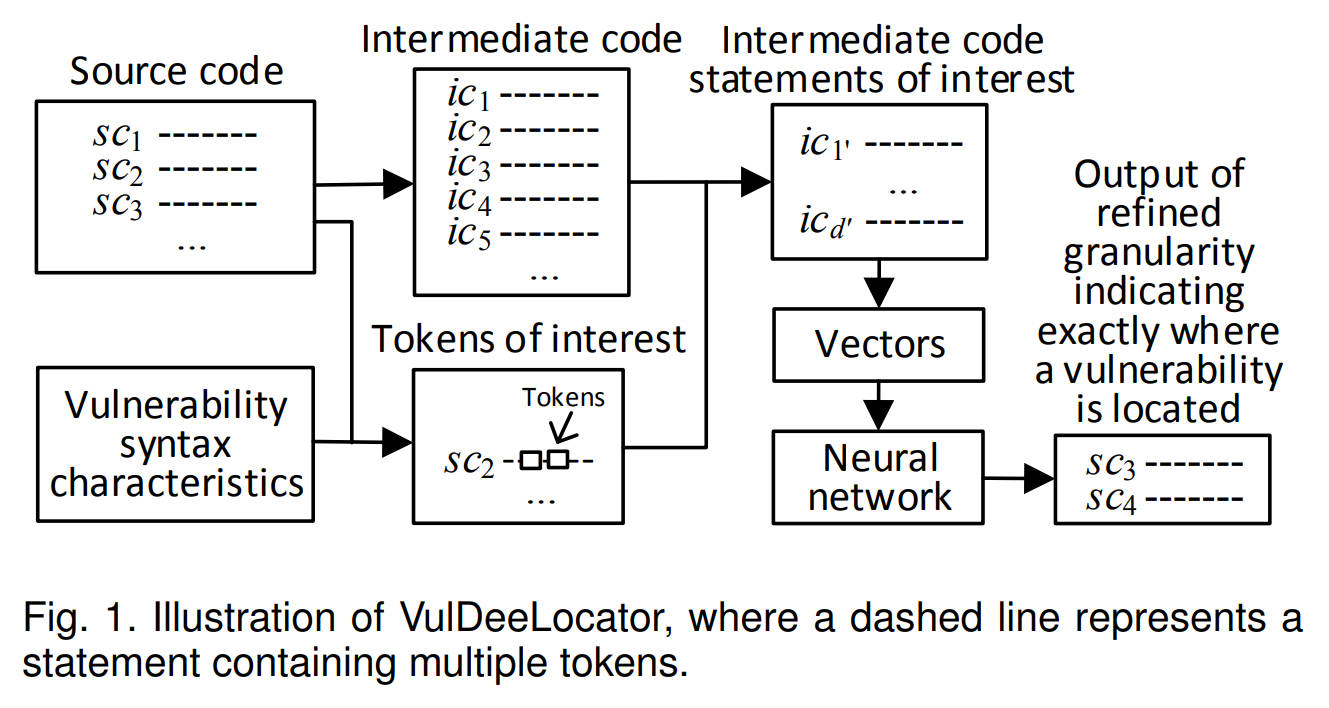
图1介绍了VulDeeLocator的基本思想。首先给定漏洞语法特征,并从源代码中提取关键tokens,然后从同一源代码的中间代码中挑选出与这些标记有语义关系的语句。这些语句被编码为向量用来训练神经网络,或者输入到训练好的模型中进行漏洞检测,得到的输出为漏洞代码的行号。
(source code- and Syntax-based Vulnerability Candidate, sSyVC)的定义:给定源程序\(P\)和漏洞语法特征集合\(H=\left \{ h_{1},…,h_{\eta} \right \}\),假设存在一个sSyVC表示为\(y_{i}\),则\(y_{i}\)是\(P\)中的一个或多个连续的匹配漏洞语法特征\(h_{q}\left ( 1\le q \le \eta \right )\)的tokens(例如标识符、运算符、常量和关键字)。
(intermediate code- and Semantics-based Vulnerability Candidate, iSeVC)的定义:给定源程序\(P\),其中间代码为\(P'\),sSyVC \(y_{i}\)的中间代码表示为\(y_{i}’\)。用\(e_{i}\)表示\(y_{i}\)对应的iSeVC,\(e_{i}\)为中间代码\(P'\)的一系列语句,这些语句与\(y_{i}’\)存在控制或数据依赖关系。也就是说,与\(y_{i}\)相对应的iSeVC是程序\(P\)的中间代码\(y_{i}’\)的一个程序切片。
3.1 整体架构
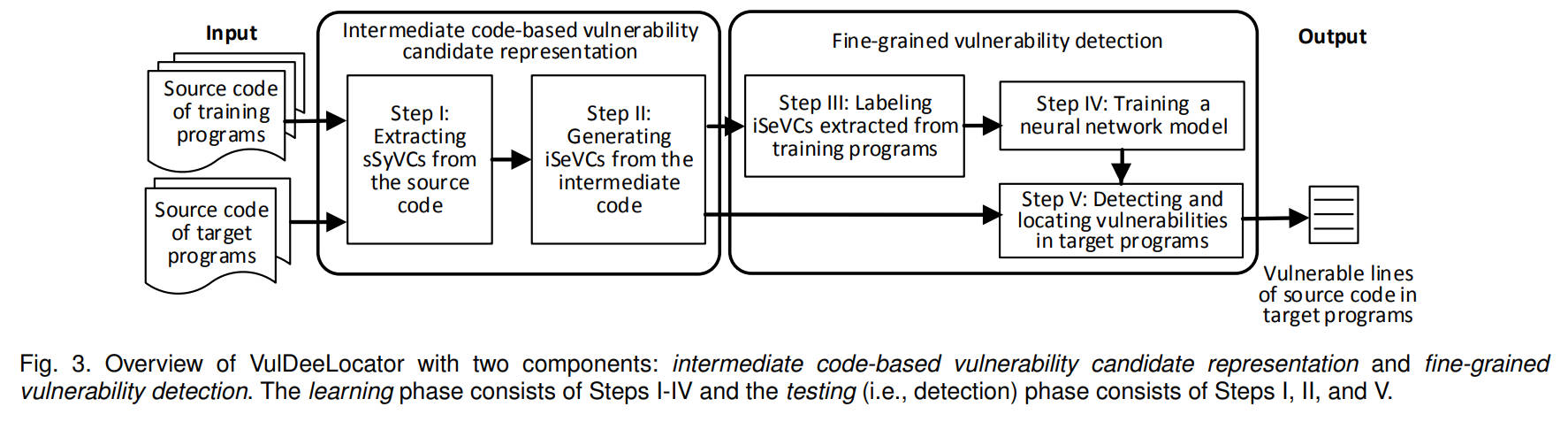
作为VulDeeLocator输入的C程序源代码需满足两个条件:
- 可以被编译为中间代码,如LLVM中间代码。
- 脆弱性程序附带漏洞位置描述,供后续定位漏洞。
VulDeeLocator大致分为5个步骤:1)从源代码提取sSyVCs。2)根据sSyVCs,从中间代码中生成iSeVCs。3)将从训练程序提取到的iSeVCs标记为有漏洞或无漏洞,并标记漏洞位置。4)通过iSeVCs对应的向量表征和标签训练神经网络模型。5)用训练好的神经网络模型去检测和定位漏洞位置。
3.2 提取sSyVCs
利用已知漏洞的语法特征,并通过程序源代码的抽象语法树来表示这些特征,从而简化sSyVC的提取。文章共定义了4种漏洞语法特征:库/API函数调用(FC)、数组定义(AD)、指针定义(PD)、算术表达式(AE)。
生成源代码的AST,然后识别其类型和代码与漏洞语法特征相匹配的节点,从中提取sSyVC。图4(a)用红框突出显示了程序中的sSyVC:与FC漏洞语法特征相关的sSyVCs包括"printf"(第6行)、"memset"(第14行和第23行)和"memmove"(第25行);与AD漏洞语法特征相关的sSyVC包括"dataBuffer"(第10行)和"source"(第11行);与PD漏洞语法特征相关的sSyVC包括"data"(第2行);与AE漏洞语法特征相关的sSyVC包括"data=dataBuffer-8"(第19行)。
3.3 生成iSeVCs

生成iSeVCs包含下列三个步骤:
- 生成链接IR文件。使用编译器(如Clang)为每个源代码生成IR文件,根据IR文件的依赖关系将其连接起来从而得到一个或多个连接的IR文件(如图4(b))。
- 生成与sSyVCs对应的IR切片。图4(c)描述了sSyVC中"data"对应的LLVM IR切片,即通过从链接的IR文件中提取控制和数据的依赖关系来生成一个依赖图,然后使用dg根据每个sSyVC对依赖图进行切片。
- 生成iSeVC。如果函数\(f_{\alpha}\)调用函数\(f_{\gamma}\),则将\(f_{\gamma}\)的IR片段中的语句附加到函数\(f_{\alpha}\)中。如果\(f_{\alpha}\)调用\(f_{\gamma}\),然后\(f_{\gamma}\)调用\(f_{\alpha}\),这种循环结构,只考虑第一个循环。图4(d)显示了用虚线框突出的函数printLine的IR片断,被附加到其调用函数main的语句"call void @printLine()"上。
3.4 标记iSeVCs
如果iSeVC包含已知漏洞,则标记其漏洞的行号,表示为\(x_{1},…,x_{\zeta }\),其中\(x_{\epsilon }\left ( 1\le \epsilon\le \zeta \right )\)对应于该漏洞的行号。否则,标记为"0"(即iSeVC不包含漏洞)。可以通过附带调试信息的文本LLVM将源代码中的漏洞行号映射到中间代码中的行号。
3.5 BRNN-vdl模型
为了在捕获程序语义信息的同时使iSeVC免受用户定义的函数名称的影响,将用户定义的函数名映射到符号名(如"FUN1"、"FUN2")。使用词嵌入方法将iSeVC编码为向量,并统一向量长度(向量长度小于\(\theta\)时,在其末尾补0。向量长度大于\(\theta\)时,将向量截断为长度\(\theta\))。
BRNN的输出粒度和输入粒度相同,无法实现细化,对于漏洞检测,iSeVC中的漏洞代码应受到神经网络模型更多的关注,BRNN-vdl较好实现了上述要求。
3.5.1 标准BRNN层
图5展示了BRNN-vdl的结构,在标准BRNN结构中新加入了3层结构:乘法层(Multiply layer)、k最大池化层(k-max pooling layer)、平均池化层(Average pooling layer)。模型的输入为标记的iSeVC的向量表征,每个时间步长对应iSeVC中的一个token,每一个token被编码为长度为30的向量,且每一个iSeVC表示为长度为27000的向量,也就是说每个iSeVC中仅考虑前900个向量。在时间步长\(\tau \left ( 1\le \tau\le \lambda \right )\)中,\(\lambda\)是iSeVC中token的数量,iSeVC的标准BRNN层的输出表示为:
\[ g_{\tau}\left(e_{i}\right)=\phi\left(g_{\tau-1}\left(e_{i}\right), g_{\tau+1}\left(e_{i}\right), e_{i}, \boldsymbol{\omega}, \boldsymbol{\beta}\right) \]
其中\(\omega\)是权重向量,\(\beta\)是偏差向量,\(g_{\tau-1}\left(e_{i}\right)\)和\(g_{\tau+1}\left(e_{i}\right)\)分别为BRNN层在时间步\(\tau-1\)和\(\tau+1\)的输出。函数\(\phi\)表示BRNN层的输出由其中几个参数表示。
对于iSeVC \(e_{i}\),标准BRNN中激活层的输出向量表示为:
\[ \boldsymbol{A}{\boldsymbol{i}}=\left(g{1}\left(e_{i}\right), \ldots, g_{\lambda}\left(e_{i}\right)\right) \]
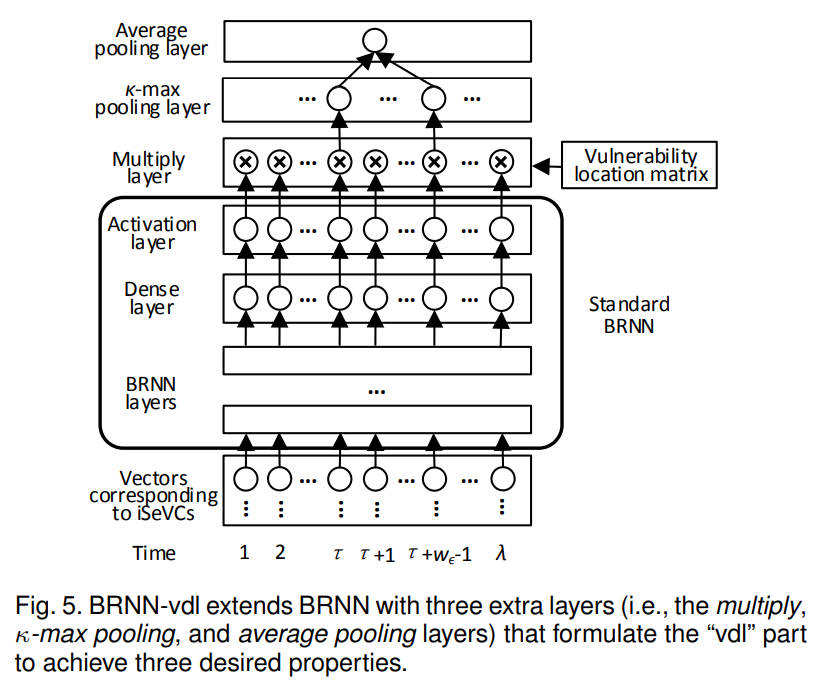
3.5.2 乘法层(Multiply layer)
乘法层实现注意力获取。对于存在漏洞的iSeVCs,挑选出与漏洞代码行对应的 tokens作为输出。对于不存在漏洞的iSeVCs,将iSeVCs中的所有tokens作为输出(这些tokens同等重要)。也就是说,乘法层的作用在于:在训练中除去与漏洞无关的tokens,提升漏洞检测精度,降低加阴率。乘法层将激活层的输出向量\(A_{i}\)与漏洞定位矩阵\(L_{i}\)相乘,得到乘法层的输出\(M_{i}\):
\[M_{i}=A_{i} L_{i}\]
其中\(L_{i}\)为对角矩阵:\( L_{i}=diag\left ( \alpha {1}, \alpha {2},…,\alpha _{\lambda } \right ) \)。对于漏洞iSeVCs,如果\(\varphi \in\left\{x_{\epsilon}^{\prime}, \ldots, x_{\epsilon}^{\prime}+w_{\epsilon}-1\right\}\),设\(\alpha _{\varphi}\)为1,否则,设\(\alpha _{\varphi}\)为0。对于不存在漏洞的iSeVCs,设\(\alpha _{\varphi}\)为1,其中\(1 \le \varphi \le \lambda\)。
3.5.3 池化层(Pooling layer)
- k最大池化层:挑选出乘法层的输出向量\(M_{i}\)中的元素前\(k\)个最大的值。
- 平均池化层:计算k最大池化层的输出的平均值。
两个池化层进一步时间检测粒度细化。对于iSeVC \(e_{i}\),平均池化层的输出定义为\(o_{i}\):
\[o_{i}=\operatorname{ave}\left(\max_{k} \left(\boldsymbol{M}_{\boldsymbol{i}}\right)\right)\]
其中函数\(max_{k}\)返回向量中前k个最大的元素,函数\(ave\)返回前k个最大的元素的平均值。
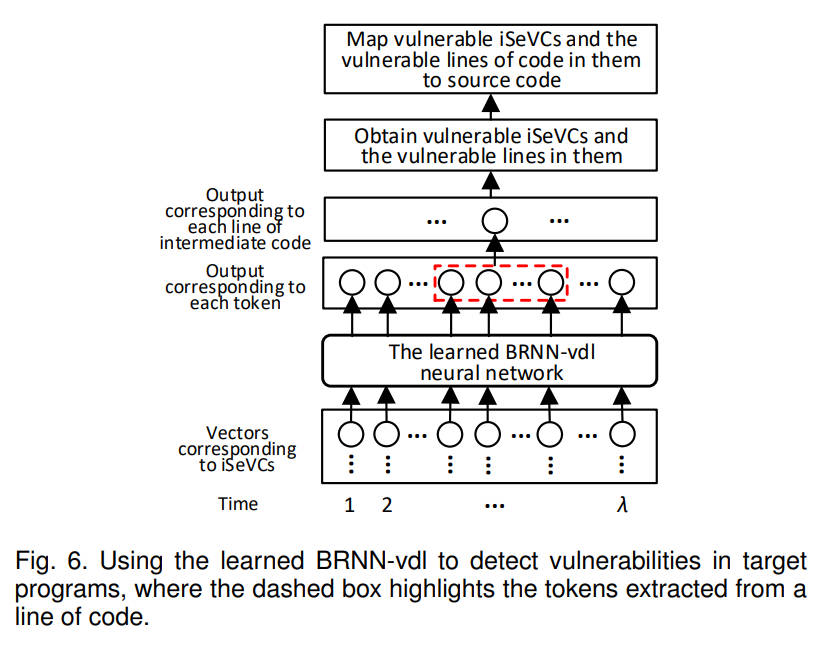
3.6 漏洞检测和定位
图6展示了已训练的BRNN-vdl进行漏洞检测和定位的过程,输入是从目标程序中提取的iSeVCs的向量表征。首先得到iSeVCs中的tokens对应的激活层的输出,并计算每一行中tokens的\(k\)个最大输出值的平均值,然后提取输出大于阈值\(\vartheta\)的代码行,从而得出存在漏洞的iSeVCs和漏洞代码行。最后,将存在漏洞的iSeVCs和其中的漏洞代码行映射到源代码中,作为检测阶段的输出。
4 实验分析
文章采用经典二分类指标FPR、FNR、A、P、F1来衡量VulDeeLocator的漏洞检测能力。使用\(IOU=\frac{\left | U\cap V \right | }{\left | U\cup V \right | }\)测试VulDeeLocator的定位精度,其中\(U\)表示真实漏洞代码行号的集合,\(V\)表示检测的漏洞代码行号的集合,IOU越接近1,说明漏洞定位精度越高。
表一展示了VulDeeLocator-BGRU基于两种不同的漏洞表征方式的漏洞检测能力对比。结果显示iSeVCs比sSeVCs(基于源代码表征)的效果更好,FPR提高4.6%,FNR提高7.4%,准确率A提升6.5%,精度P提升5.9%,F1值提高6.7%。这表示基于中间代码表征的iSeVCs与基于源代码表征的sSeVC相比可以捕获更多的语义信息。

为了验证BRNN-vdl对于漏洞定位的有效性,分别基于不同漏洞候选表征和不同模型进行了实验,表4总结了实验结果。BRNN-vdl在IOU值上比BRNN平均提高了21.5%,在输出的漏洞行数上,BRNN-vdl平均为2.6行,而BRNN平均为18.8行。当使用sSeVC作为漏洞候选时,FPR降低5.0%,FNR提高0.5%,F1值提高4.2%;当使用iSeVC作为漏洞候选时,其FPR提高1.8%,FNR提高1.6%,F1值提升3.9%。以上结果说明,与BRNN相比,BRNN-vdl实现了更高的漏洞定位精度和略高的漏洞检测能力。
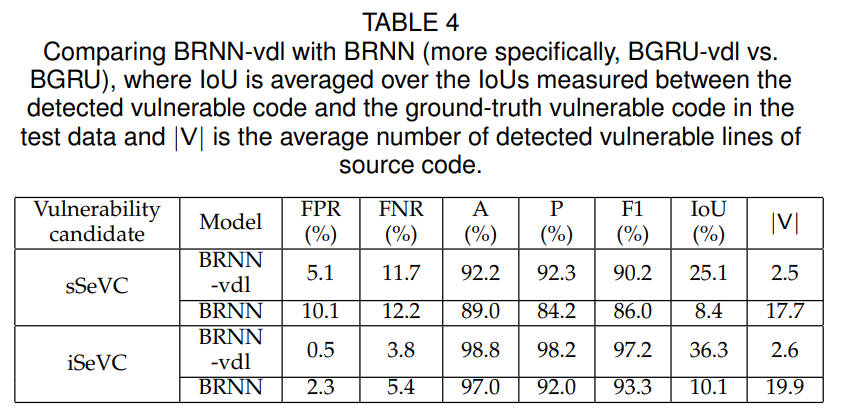
表5总结了与目前最先进的基于模式的漏洞检测器的比较结果。VulDeeLocator在检测和定位漏洞方面比最先进的基于模式的漏洞检测器更有效。特别是,VulDeeLocator-BGRU的定位精度平均比漏洞检测器SySeVR高4.2倍。

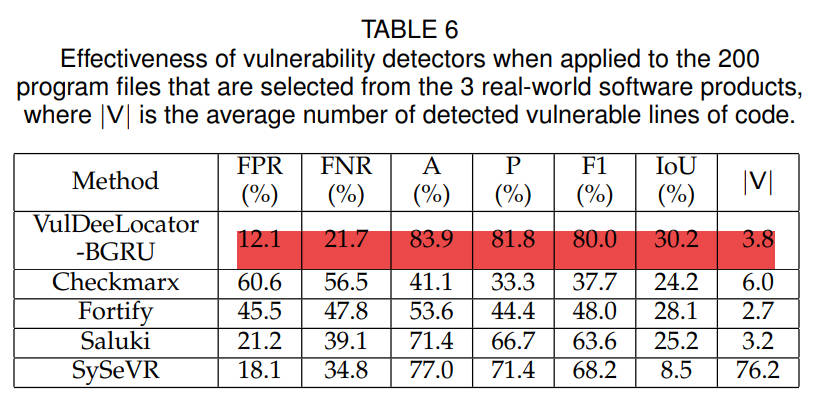
为了测试VulDeeLocator是否能检测并定位真实软件产品中的漏洞,从3个真实软件产品中随机挑选了200个程序,在5个漏洞检测器中,VulDeeLocator-BGRU是最有效的。在其他4个检测器中,SySeVR获得了最高的F1值,但其IoU最低。SySeVR的低定位精度是由于检测到的漏洞代码行的平均数量很大(即平均每个检测到的漏洞有76.2行代码),这与VulDeeLocator检测到的漏洞代码行的平均数量3.8行形成强烈对比。
5 个人总结
5.1 总结
这篇文章提出了一种基于深度学习的,具有高检测能力和高定位精度的漏洞检测器VulDeeLocator。通过引入粒度细化的理念和利用基于中间代码的表征来捕获程序中的语义信息,如类型和宏的定义及其在文件中的使用之间的关系,以及控制流和变量定义-使用关系。真实软件产品的检测结果显示,VulDeeLocator检测到了NVD中没有报告的四个漏洞。
5.2 VulDeeLocator存在的缺陷
- 仅支持C源程序中的漏洞检测,不适用于其它编程语言。
- 用于检测的程序源代码必须能成功被编译为中间代码,无法正常通过编译的代码不能使用。
- 在NVD数据集中,将\(diff\)文件的删除或移动的代码行作为漏洞位置,没有考虑\(diff\)文件中仅涉及行添加的漏洞。SARD数据集无法代表真实软件产品。
- 为达到漏洞定位目的,需要量身定制神经网络(如BRNN-vdl)。
- 作为一个静态检测漏洞检测器,无法识别依赖于动态信息的漏洞。

2022年11月8日 16:11 沙发
牛逼哄哄的,来学习如何看论文,火钳刘明
2022年11月13日 21:21 1层
@Jungle 共同努力!