
- A+
二进制代码相似性检测的目的是在无法访问源代码的情况下检测相似的二进制函数,是计算机安全领域的一项重要任务。传统方法通常使用图匹配算法,速度慢且不准确。基于神经网络的方法将二进制函数表示为包含人工选择块特征的控制流图(CFG),并采用图神经网络(GNN)计算图嵌入,但它们无法捕获二进制代码的足够语义信息。文中提出了语义感知神经网络来提取二进制代码的语义信息。具体来说,使用 BERT 对一个 token 级任务、一个块级任务和两个图级任务中的二进制代码进行预训练,并采用卷积神经网络(CNN)从邻接矩阵中提取节点的顺序信息。结果表明,该方法优于最先进的模型。
1 问题描述
二进制代码相似性检测在计算机安全领域有很多应用,包括代码克隆检测、漏洞发现、恶意软件检测等。基于图匹配的方法速度非常慢,而且可能难以适应不同的应用。最近一种基于神经网络名为 Gemini 的方法,它首先将二进制代码转化为 CFG,其中每个块中包含人工选择的特征。然后使用 Structure2vec 生成图嵌入。最后,在二进制函数上连接这些块结构,以计算相似性得分并减少损失。
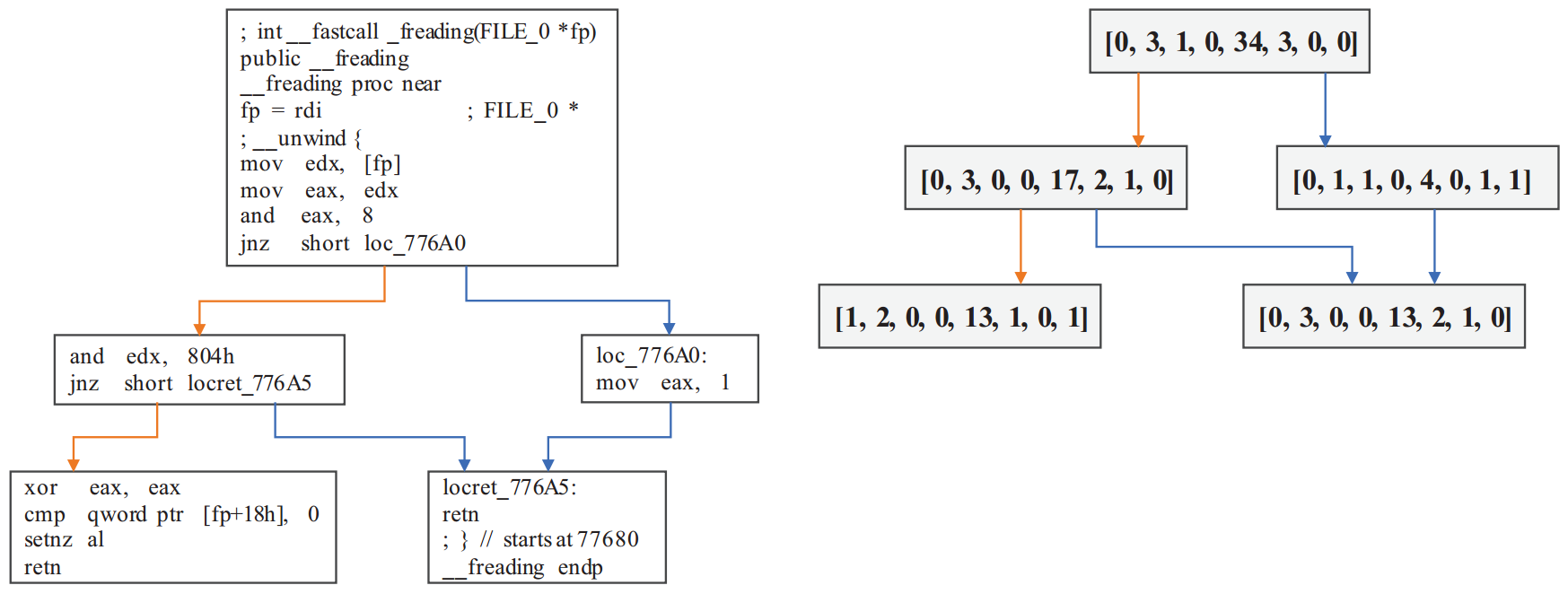
尽管该方法已经取得不错的效果,但仍存在一些问题:
- 每个区块为人工挑选特征的低维嵌入表示,导致大量语义信息丢失。
- 没有考虑提取节点的顺序信息,这在表示二进制函数时起着重要作用。
2 解决方案
为了解决上述两个问题,论文提出了一个包含三个模块的框架:语义感知模块、结构感知模块和顺序感知模块。
在语义感知模块中,将 CFG 代码块中的 token 视为单词,代码块视为语句,并采用 BERT 进行预训练。它另外包括两个图级任务:块内图任务(block inside graph task, BIG),用于确定两个采样的代码块是否在一个图中;图分类任务(graph classification, GC),用于区分代码块属于哪个平台/优化。
在结构感知模块中,使用带有 GRU 的 MPNN 模型来更新函数,与只使用 tanh 函数相比,在每一步使用 GRU 可以存储更多信息。
在顺序感知模块中,利用 CFG 的邻接矩阵和 CNN 模型提取节点的顺序信息。
3 方法架构
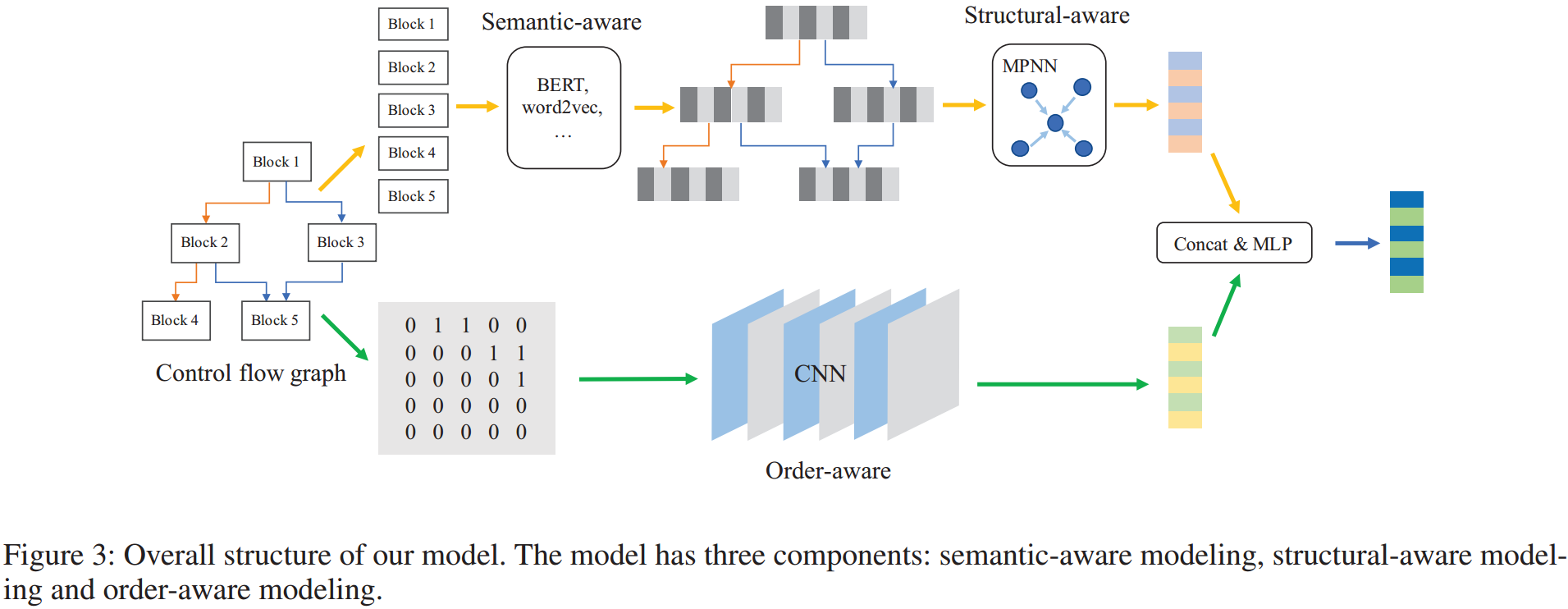
3.1 总体结构
模型的输入为二进制代码函数的 CFG。如图 3 所示,在语义感知部分,模型将 CFG 作为输入,并使用 BERT 对 token 嵌入和块嵌入进行预训练。在结构感知部分,使用带有 GRU 的 MPNN 更新函数,并计算图语义和结构嵌入 gss。在顺序感知部分,模型以 CFG 的邻接矩阵为输入,采用 CNN 计算图顺序嵌入 go。最后将它们串联输入到 MLP 层计算图嵌入 gfinal。
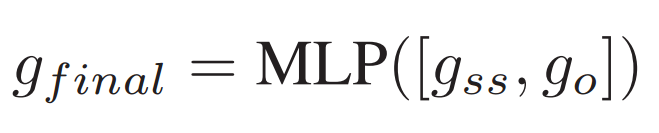
3.2 语义感知模块
在语义感知模块,针对 CFG 提出了一个包含 4 项任务的 BERT 预训练模型:一个 token 级任务(MLM)、一个块级任务(ANP)以及两个图级任务(BIG 和 GC)。
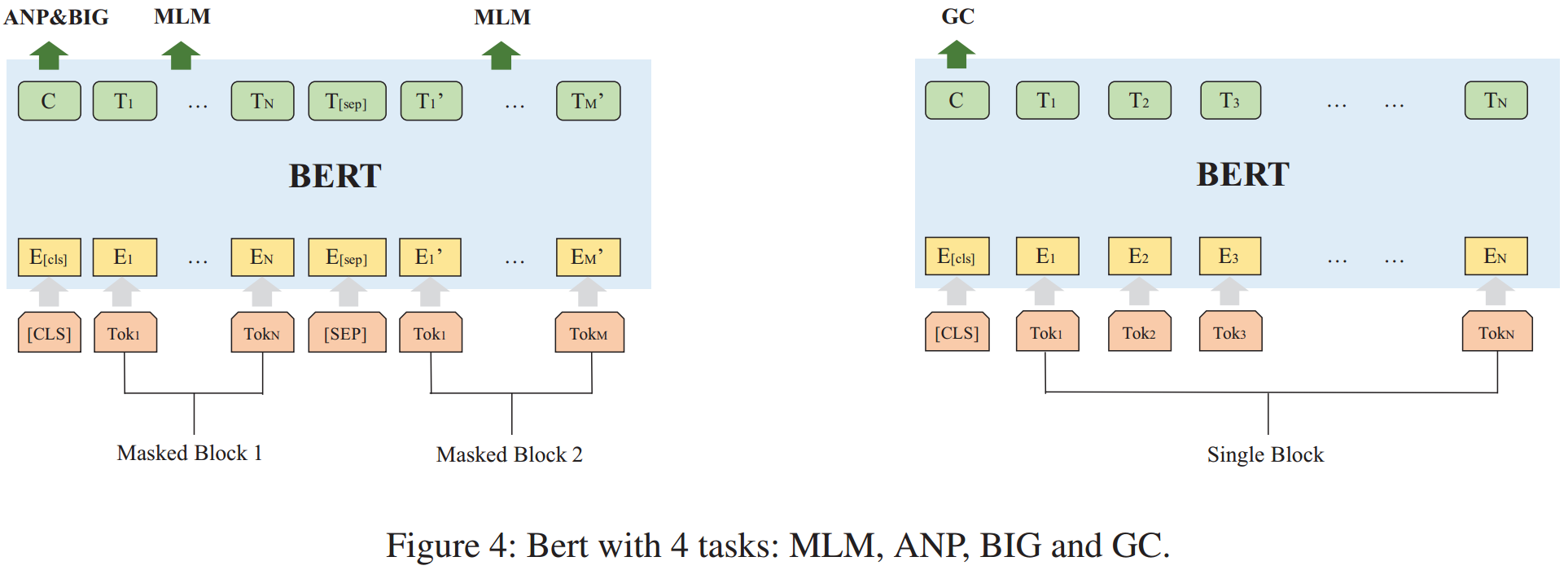
(1)屏蔽语言模型(MLM)。MLM 用于提取块内的语义信息,是一个 token 级任务,它在输入层对 token 进行屏蔽,并在输出层对其进行预测。
(2)邻接节点预测(ANP)。在图中,块的信息不仅与块本身的信息有关,还与其邻居的信息有关。ANP 用于提取图中所有相邻的块,并在同一图中随机抽取几个块来预测两个块是否相邻。
(3)图内块任务(BIG)。BIG 任务试图让模型判断两个节点是否存在于同一个图中。在该任务中,随机抽样在同一图中/不在同一图中的块对,并对其进行预测,有助于模型理解块和图之间的关系。
(4)图分类任务(GC)。在不同的编译选项下,图和块的信息可能不同。为了让模型区分这些差异,设计图分类任务(GC),可以让模型对不同平台、不同架构或不同优化选项下的块进行分类。
3.3 结构感知模块
从 BERT 预训练中获得块嵌入后,使用 MPNN 计算每个 CFG 的图语义和结构嵌入。消息传递阶段信息函数 M 和更新函数 U 运行 T 个时间步,然后读出函数 R 计算整个图语义和结构嵌入gss。$h_{v}^{0}$ 表示 BERT 生成的初始块嵌入,$h_{v}^{t}$ 表示时间步 t 时刻的块嵌入。
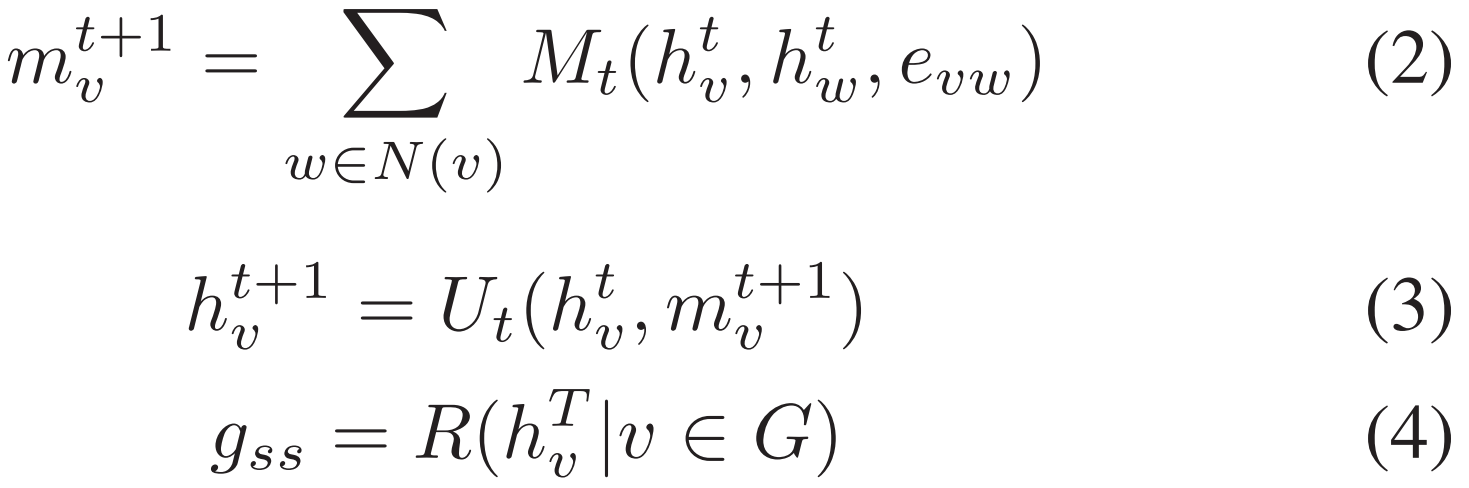
其中 G 表示整个图,v 表示图节点,N(v) 表示节点 v 的邻居节点。在信息函数 M 上使用 MLP,在更新函数 U 上采用 GRU 来学习时间迭代的序列信息。并使用求和函数,提取第 0 步和第 T 步的图表征。
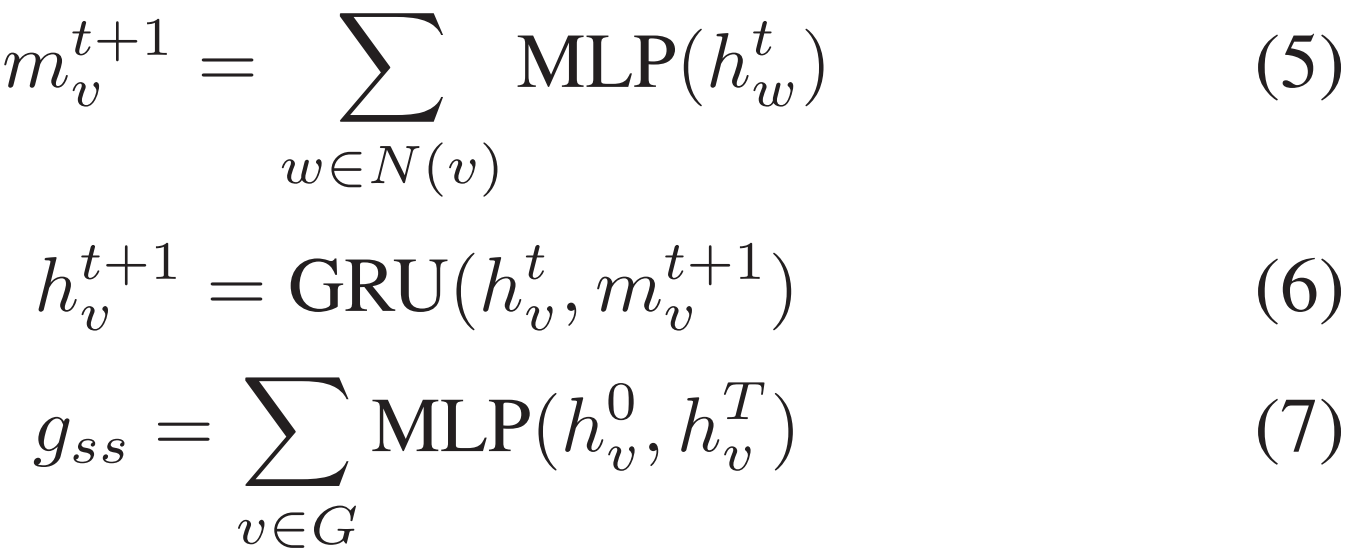
3.4 顺序感知模块
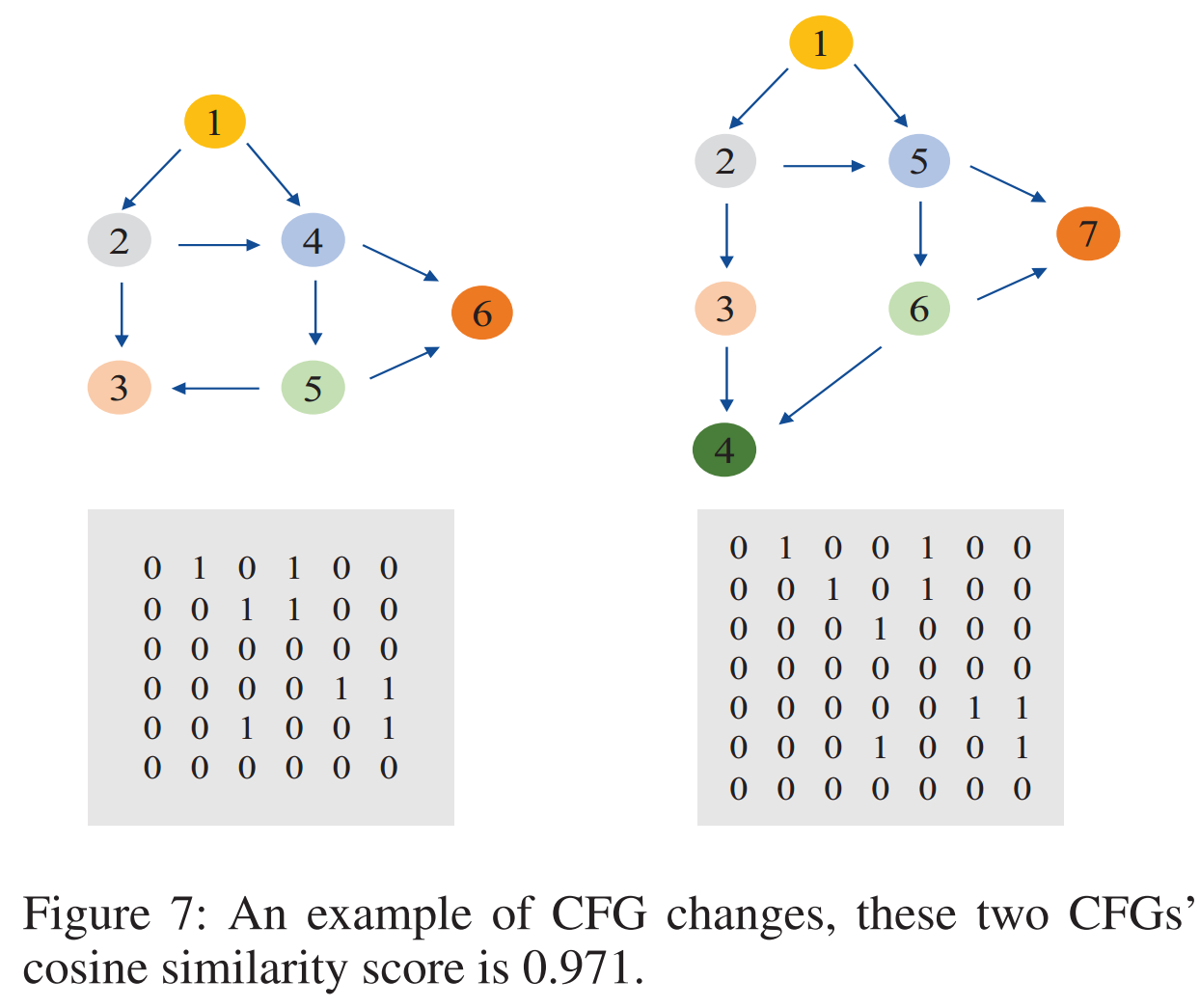
图 5 展示了三个图及其邻接矩阵,可以观察到图中的三角形对应的邻接矩阵都为正方形,具有一些共同特征。对比 5a 和 5b,三角形上增加了一个新节点,但三角形的节点顺序并没有被打破,邻接矩阵中的三角形特征未发生变化(仍然是1、1、0、1),即使位置发生了变化。CNN 模型具有平移不变性,可以捕获这些信息。初步观察 5c,新加入的节点 2 似乎打破了三角形的节点顺序,但是移动邻接矩阵的第二行和第二列,三角形特征正方形依然存在。类似于图像缩放一样,将三角形特征方阵视为 2*2 的图像,那么在 5c 中,它被放大为 3*3 的图像。CNN 模型具有尺度不变性,也可以学习到这些信息。
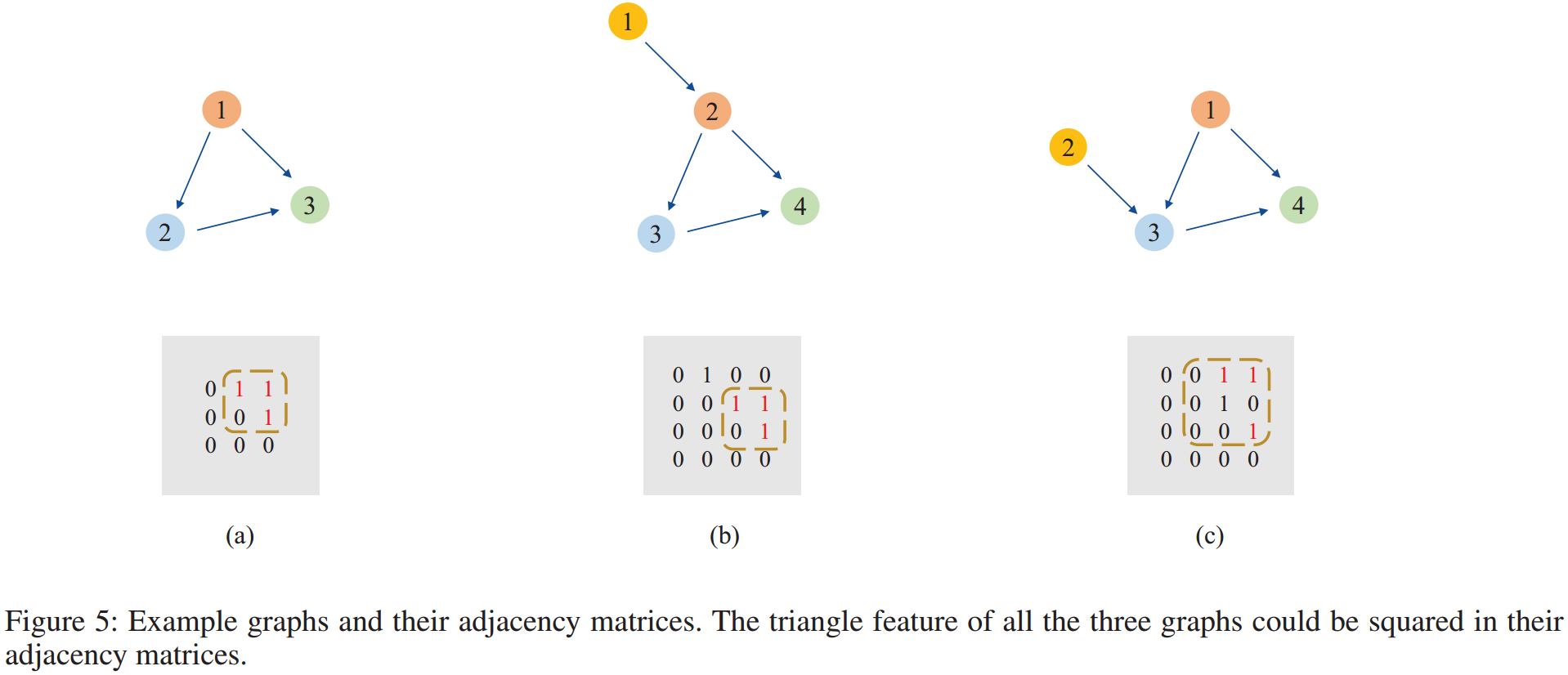
在二进制代码相似性检测任务中,同一函数在不同平台上编译时,节点顺序 通常不会发生很大变化。大多数节点顺序变化都是增加一个节点、删除一个节点或交换几个节点,因此 CNN 在在该任务中非常有用。

如公式 8 所示,将邻接矩阵 A 作为输入,采用 Resnet (包含 3 个残差块的 11 层 Resnet) 传输信息,利用最大池化来计算图序嵌入。其中所有特征图大小都为 3*3,旨在学习图的微小变化。
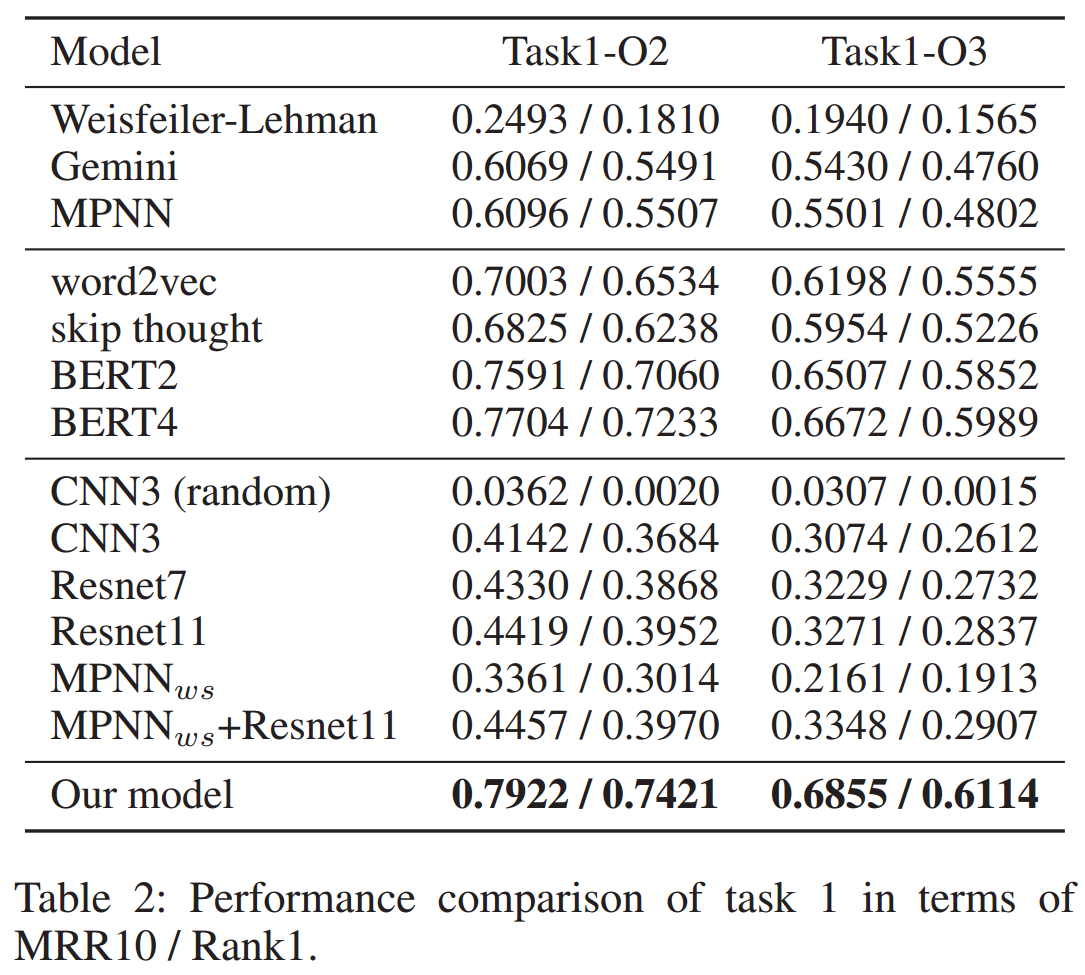
4 实验评估


5 论文总结
文中提出了一种新的二进制代码图学习框架,其中包含语义感知模块、结构感知模块和顺序感知模块。首先提出用两个原始任务 MLM 和 ANP 以及两个额外的图级任务 BIG 和 GC 对 CFG 块进行预训练,用于捕捉语义特征。然后使用 MPNN 提取图结构信息。最后利用 CNN 模型来捕捉节点顺序信息。文中在四个数据集对两个任务进行了实验,实验结果表明,提出的模型优于目前最先进的方法。
6 原文链接
论文题目:Order Matters: Semantic-Aware Neural Networks for Binary Code Similarity Detection
论文出处:The Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI 2020)
项目地址:无
