
- A+

1 存在问题
软件程序趋于庞大和复杂,软件漏洞成为计算机安全的主要威胁之一。开源软件的发展使得源代码漏洞检测变得越来越关键。传统的漏洞检测方法由于假阳率和假阴率较高,无法满足复杂软件的分析需求。
2 提出方法
提出了一个基于混合语义的图神经网络漏洞挖掘系统HyVulDect。该系统构建了一个复合语义的代码属性图来表示代码,使用门控图神经网络提取深层语义信息。利用污点分析提取污点传播链,并使用BiLSTM模型获取上下文的token级别的特征,最后使用分类器对融合特征进行分类。同时,加入双重注意力机制,使得模型能够关注与漏洞相关的代码。
3 本文贡献
- 提出了一种基于混合语义的图神经网络漏洞挖掘系统,该系统利用门控图神经网络和具有双注意机制的BiLSTM网络来提取源代码图级和token级别特征。融合两个维度的深度特征可有效用于检测漏洞。
- 通过补充程序切片结构,改进了基于API调用的程序切片算法,提取漏洞上下文的同时保留了代码的结构信息。
- 实验表明,HyVulDect检测性能优于传统的静态扫描工具。与最先进的探测器相比,Devign、VUDDY和BGNN4VD的精度分别提高了27.6%、14.2%和4.9%。同时,它可以有效检测存在的CVE漏洞。
4 方法介绍
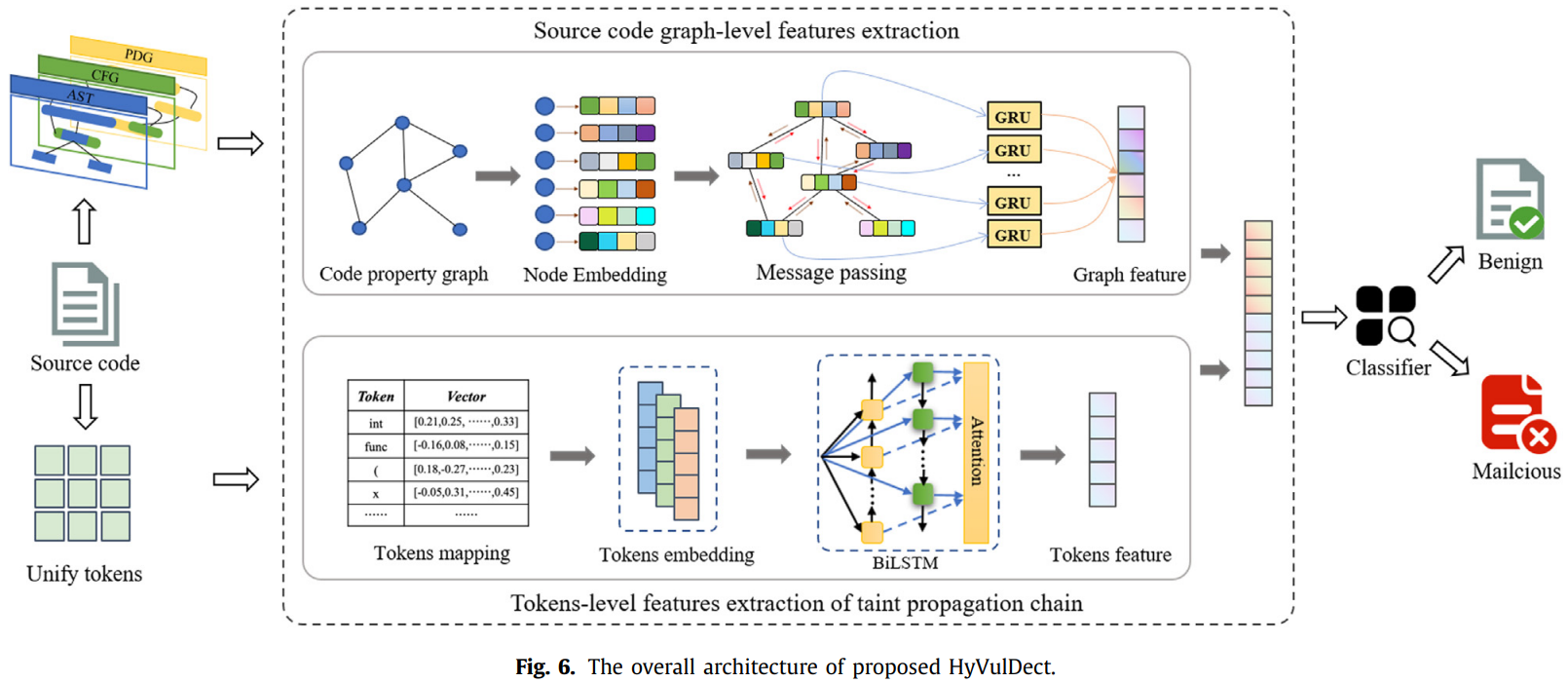
4.1 源代码图级特征提取
首先确定危险函数,根据危险函数的参数传递路径回溯所有相关代码行,并按初始顺序排列这些关键代码得到程序切片。统一替换用户自定义的函数名和变量名,例如将函数名替换为func_N(N=0,1,...,n),变量名替换为var_N(N=0,1,...,n),用于消除不同命名引起的误差和降低编码后的向量维度。这种方式提取了语义相关的代码,但破环了原始的代码结构,因此需补充程序切片的结构。
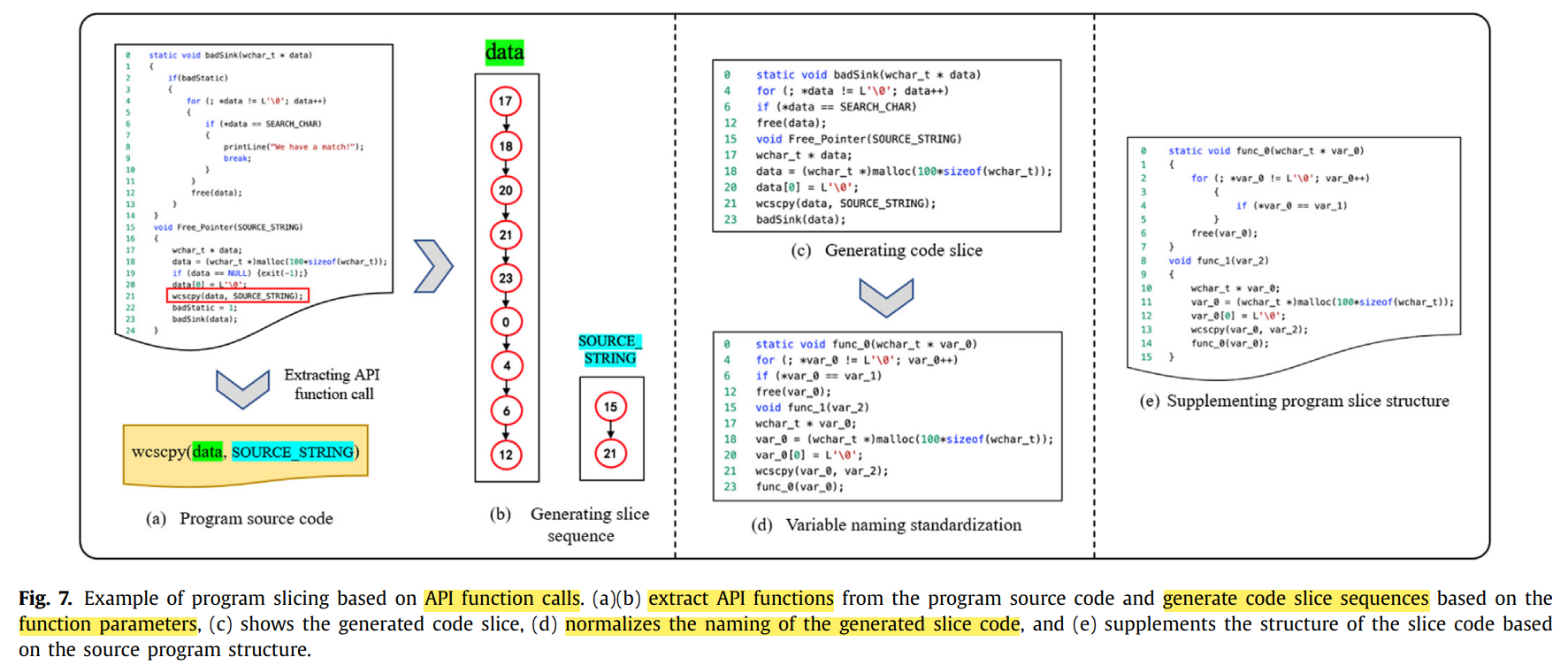
图7展示了一个基于API函数调用的程序切片例子。首先,定位API函数wcscpy,它存在两个参数data和SOURCE_STRING,通过参数data回溯所有与其相关的代码行,即17->18->20->21->23->0->4->6->12;通过参数SOURCE_STRING回溯所有与其相关的代码行,即15->21。根据程序代码原始顺序组合上述二者,得到切片序列:0->4->6->12->15->17->18->20->21->23(图7(c))。
为了减少token的数量和编码后的向量长度,对代码切片中的自定义的函数名和变量名统一替换。由于代码切片破环了源程序的结构,利用算法1补充代码切片的结构。算法1主要思想如下:从上往下扫描代码切片,在用户自定义的函数行下方添加"{",直到遇到不属于用户自定义的代码行,在其前添加"}"。首先完成函数结构的补充,再按同样的方法完成其中的控制结构(if语句,switch语句,for循环和while循环),最终得到完整结构的代码切片(图7(e))。

使用Joern将源代码解析为图形数据,将代码属性图(CPG)中的控制流边和数据依赖边合并为新的边CAD。通过DGL构建图形数据,对于图中的节点和边缘特征,使用预训练的Word2vec模型对其向量化。为每一个单词分配一个向量,由于97.7%的节点特征长度小于20,因此设置特征最大长度为20,从末尾阶段大于20的特征向量,并使用0来补充小于20的向量。总共存在以下5种类型的节点边:CDG: 0; DDG: 1; AST: 2; CFG: 3; CAD: 4。
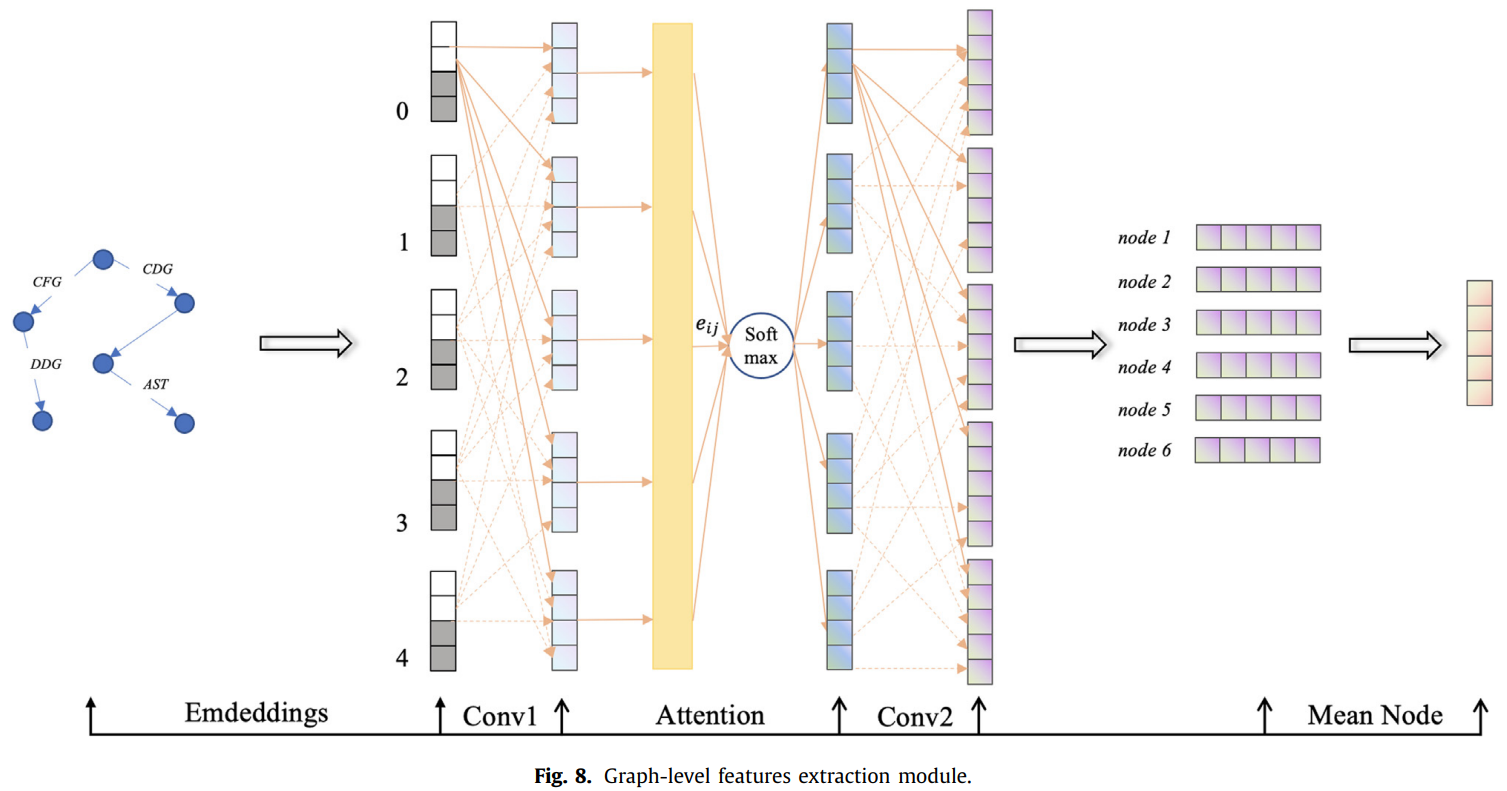
最后构建基于门控图神经网络的检测模型,用于学习漏洞代码的语义信息。同时引入注意力机制,使得模型更加关注与漏洞相关的节点。图8展示了图级特征提取模型。首先,使用门控图卷积层提取一些低级特征,然后引入归一化层,可以使较大的学习速率对于梯度传播更稳定,并提高网络的泛化能力。使用sigmod函数作为激活函数,然后利用图形注意层提取更高级别的特征,使用ReLu函数激活神经元,并使用参数为0.3的dropout层。这可以减少模型的大小,同时提高模型的收敛速度并防止过拟合。最后,覆盖另一层图卷积层以提取最高层的特征,多个卷积层能够从较低级别的特征中迭代提取更复杂的特征。
4.2 污点传播链的token级特征提取
尽管复合图结构可以合成各种语义信息,但无法检测触发条件更为复杂的漏洞。污点分析可以跟踪和分析程序中的污点信息流。使用污点分析的方法提取源代码中的源->汇聚点传播链。为了简化跟踪过程和减小代码大小,通过跟踪变量分析污染信息流,并使用队列记录被污染的变量,从而提取源代码的污点传播链。利用相同的方法进行预处理,使用Word2vec预训练模型进行向量化。由于91.4%的污点传播链token数不超过800,因此选择800作为所有向量的阈值。同时考虑到在源代码分析中,某些特殊token符号可能包含丰富的语义信息,使用词法分析技术对token进行分割,以最大限度地分离不同的标识符和其它符号。
为了捕获污点链的上下文语义信息,使用BiLSTM进行token级的特征提取。
4.3 漏洞分类
在提取完污点传播链的源代码图级特征和token级特征之后,将它们串联得到最终的漏洞代码特征。基于CPG的图级特征包含源代码数据依赖性、控制依赖性和其他语义信息。基于污点分析的token级特征包含漏洞代码上下文语义信息和代码序列语法信息。最终获得的特征包含了代码的结构、语法和语义信息,可以覆盖多种类型的漏洞。最后利用XGBoost算法进行漏洞分类。
5 实验评估
5.1 数据集
- Software Assurance Reference Dataset (SARD)
- FFmpeg、Qemu、PHP、OpenSSL、Libav、Linux开源项目的CVE漏洞和补丁源代码
预处理:删除所有注释,根据diff文件的标记,提取并标记补丁文件和漏洞文件中的相关函数,并将补丁函数标记为"0",漏洞函数标记为"1"。
5.2 实验对比
与存在的方法和检测工具的对比:
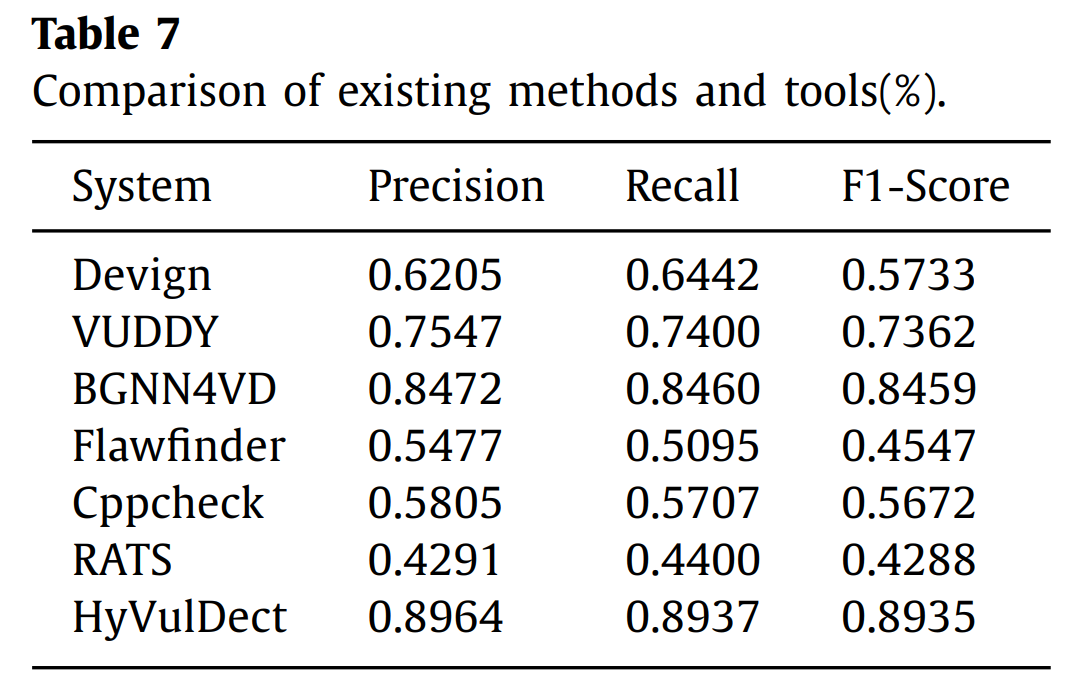
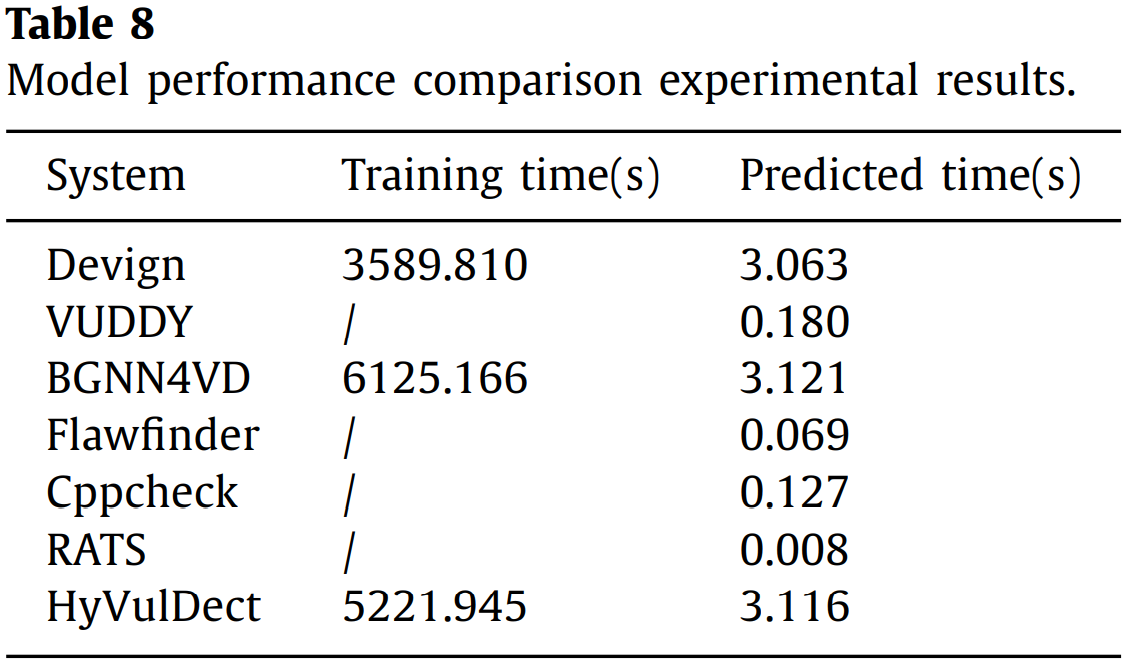
模型性能比较:
HyVulDect在真实世界软件产品中检测到的漏洞(部分):

