
- A+
1 RAG
1.1 RAG的定义
RAG(Retrieval-Augmented Generation,检索增强生成) 是一种结合了 信息检索(Retrieval)和 生成模型(Generation) 的方法。它的核心思想是:在生成文本前,先从外部知识库或文档中检索相关信息,并将这些信息作为额外上下文输入给生成模型,从而提升生成结果的准确性、可靠性,克服大模型的幻觉。
1.2 RAG的一般流程
- 知识库构建:文本/代码/图片 -> Embedding -> Vectors -> 生成向量数据库/知识库(包括Pinecone、Chroma、PostgreSQL-pgvector等)。
- Retrieval(检索):Prompt -> Embedding -> Vectors -> 外部数据库(如向量数据库)中检索匹配。
- Fusion and Generation(融合生成):
- 将检索到的内容与原始 prompt 拼接或融合。
- 调用 LLM(如 GPT、LLaMA、Mistral)生成答案。
RAG 已经从 单纯检索+生成,逐渐演进到 动态检索、自适应生成、结构化知识融合、多模态扩展、智能体驱动 的路线,未来趋势是让 LLM 更好地利用外部知识,并具备自主决策能力。
向量数据库格式:[嵌入向量 : 文本]
传统数据库格式:[文本 : 文本]
2 GraphRAG
2.1 GraphRAG的定义
GraphRAG(Graph-based Retrieval-Augmented Generation) 是一种 将图结构知识引入 RAG 框架 的方法。与传统 RAG 仅依赖向量检索不同,GraphRAG 通过 图数据库/知识图谱 来组织、存储和检索信息,使得生成模型不仅能看到相关的文档片段,还能理解实体之间的关系和上下文语义结构。
换句话说:
- 普通 RAG = 把文本切成碎片(改过程称为 Chunking),按语义相似度(如 Embedding 后的向量余弦值、欧式距离、点积等)查询和匹配。
- GraphRAG = 把知识组织成图(节点+边),不仅查到“相关内容”,还能查到“相关关系”。
2.2 GraphRAG的核心步骤
- 构建知识图谱:从文本或数据库中抽取 实体(nodes) 和 关系(edges)。
- 图检索(Graph Retrieval):输入查询后,先在图谱中找到相关节点;可进行 邻居扩展(neighbor expansion) 或 多跳推理,找到更完整的上下文。
- 上下文组装(Context Assembly):把检索到的子图转化为文本或结构化上下文(如三元组)。
- 增强生成(Augmented Generation):将子图信息 + 用户问题一起输入大模型,生成更加准确的回答。
文档级 GraphRAG 流程:长文档切分(chunking: 以单词、语句或段落为单位)-> 抽取 关键词、实体、关系 -> 构建成 局部知识图谱,节点表示 实体,边表示关系 -> 检索图谱相关部分作为上下文,融合 User Prompt 交给 LLM 生成答案。
跨文档级 GraphRAG 流程:长文档切分 -> 将不同文档中的实体进行 对齐与去重 -> 将实体和关系合并,构成一个 跨文档大图谱 -> 在问答时,跨越不同文档找到答案路径,实现 知识融合与多跳推理。
2.3 图结构
2.3.1 构建流程
Labled Property Graph (LPG):实体(节点) + 关系(边) + 属性(节点内容属性)
Data Cleaning:提取 实体、关系、属性 + prompt"不要编造结果!" -> LLM -> 构建LPG -> 再次反馈给LLM并询问(如: 构建好的LPG + prompt"还有没有要补充的?") -> 直至 LLM 给出最终结果/LPG。
另外,还可以通过 莱顿社区检测算法(Leiden algorithm)来 抽象和简化 知识图谱,使 LLM 可以正确推断出 文中没有出现过的信息。
最后,该知识图谱(节点、边的实体信息、总结性描述)和原文中的所有文本切片 都经过 Embedding 存入向量数据库中,供后续检索使用。
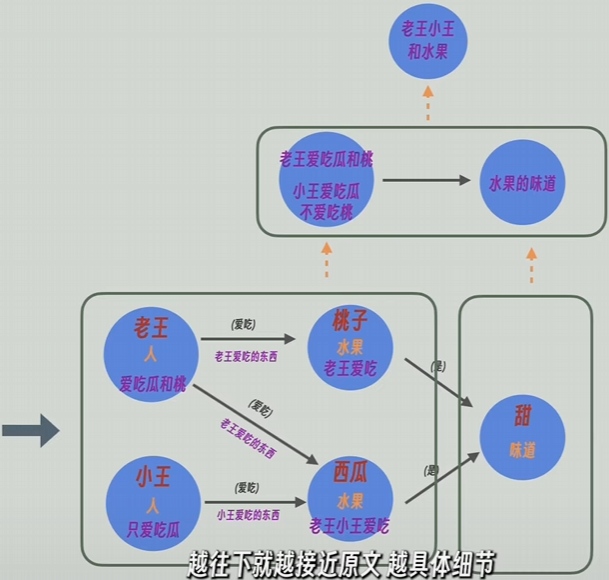
例如下图:层级越网上,信息就越抽象、精炼;越往下就越接近原文和具体细节。
2.3.2 GraphRAG的检索方式
在检索查询过程中,可以选择查询知识图谱的某一层或某几层,也可以选择只查询原文。
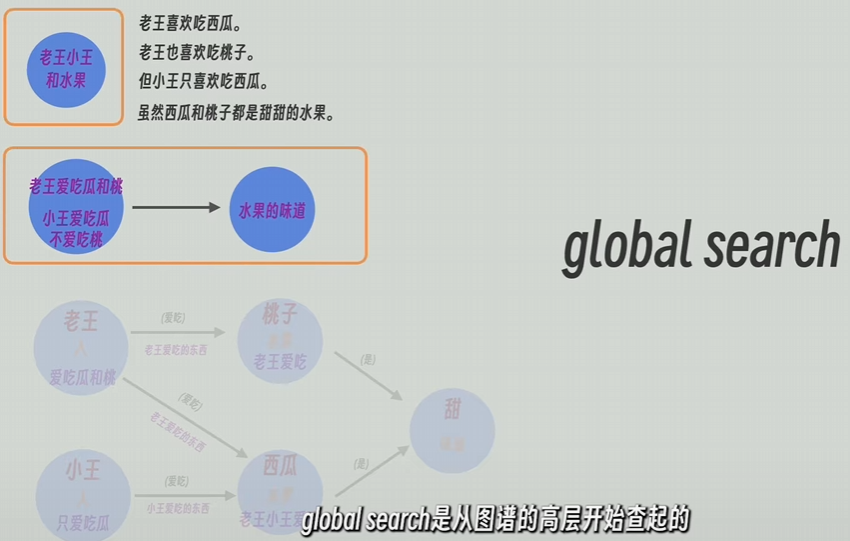
(1)Local Search 策略。会先从最底层的知识图谱里面找出和问题最接近的实体(GraphRAG 会维护图谱军儿原文之间的映射关系),一旦找到相关的图谱点,GraphRAG 就会反向查询 这些点和边是由哪些原文生成的,以及它们出现在哪些上层的图谱结构里面,和它们相邻的节点和边的信息。
最后 GraphRAG 找到:
- 所有这些点和边的总结性描述;
- 它们关联的原文片段;
- 用户提的问题;
将它们一起发送给 LLM。
(2)Global Search 策略。从图谱的高层开始查询,一层一层往下查询,更适合回答 偏抽象,全局性更强的问题(比如 文章的核心观点是什么?)。
3 思考
单个函数 -> 抽取实体、关系、属性 -> Source-Sink -> LPG;
多个函数 -> 多个LPG -> 对齐与去重 -> 代码文件级知识图谱;
文件级知识图谱 -> 莱顿社区检测算法(Leiden algorithm) -> 密集节点合并 -> 精简后的知识图谱;
4 参考
LLM Embedding Rank:MTEB Leaderboard - a Hugging Face Space by mteb
