
- A+
深度学习已在众多二进制分析任务中展示了其优势,包括函数边界检测、二进制代码搜索、函数原型推理、值集分析等。现有方案忽略了复杂的指令内结构,主要依赖于控制流,其中上下文信息是嘈杂的,并且可能受到编译器优化的影响。为了解决上述问题,文中提出了一种预训练汇编语言模型,PalmTree,利用三个预训练任务来捕获汇编语言的各种特征,帮助生成高质量表示。实验结果表示,在所有下游任务中 PalmTree 都优于其他指令嵌入方案。
1 问题描述
将深度学习应用于二进制分析任务时,输入大致分为三种:原始字节码、人工提取的特征和通过模型学习到的向量。原始字节码丢失过多信息,人工提取的特征容易出错且耗费人力;通过模型学习指令表征拥有两个优点:(1)避免人工设计工作,降低成本和减少出错概率;(2)可以学习更高级别的特征,而不是单纯的语法特征。
目前通过模型学习指令表征的方法存在下列问题:
- 忽视了指令内部复杂的结构,将整条指令视为一个单词或只考虑简单的指令格式。
- 部分方法使用控制流图(CFG)捕捉指令间的上下文信息,忽略了因编译器优化导致的噪声,无法反映指令之间的实际依赖关系。
2 解决方案
文中提出的解决方案如下:
- 在指令嵌入过程中考虑了操作码、寄存器、立即数、字符串、符号等。
- 在指令分词阶段通过 [str] 替换字符串,通过 [addr] 有条件地替换常量,有效解决了词汇溢出(OOV)问题。
3 模型架构
PalmTree 共由三个部分组成:指令对采样、指令分词和汇编语言模型。
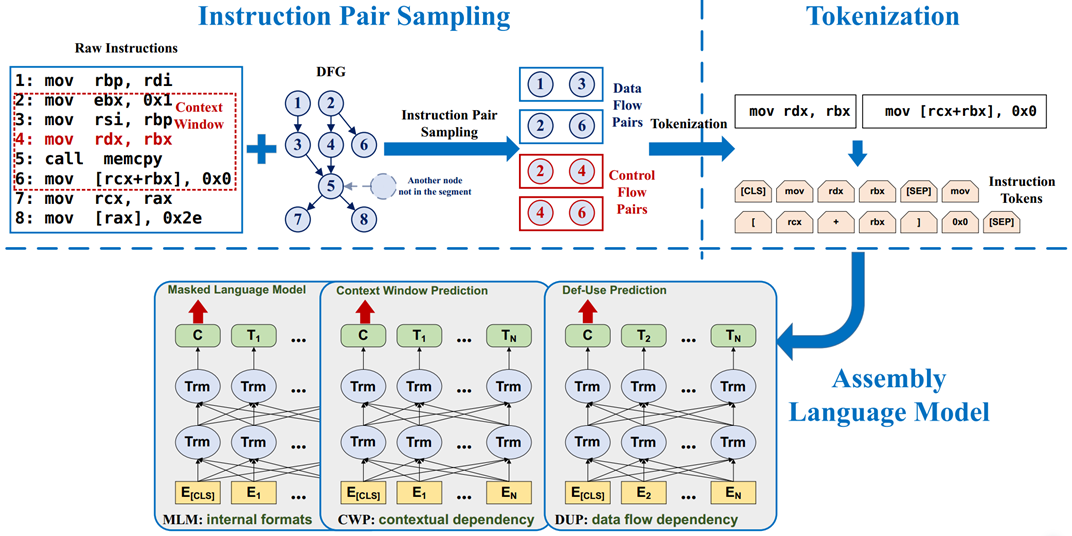
3.1 指令对采样
该模块用于生成模型的输入。首先通过 Ninja 对二进制文件进行反汇编得到汇编代码;然后在这些汇编代码中确定每个操作数与其依赖指令间的 def-use 关系。最后从控制流序列中提取指令对样本(用于后续 CWP 任务),基于 def-use 关系从数据流序列提取指令对样本(用于后续 DUP 任务)。
3.2 指令分词
该模块将指令视为 sentences,将指令中得操作码,寄存器等视为 words(tokens)。作者在该阶段设计了一种标准化方法用于防止 Embedding 过程中的词汇表溢出(OOV)问题:
- 用符号 [str] 代替指令中的常量;
- 有条件地替换常量:当 16 进制常量的长度 >= 5 时,替换为 [addr];当 16 进制常量的长度 < 5 时,保留并编码为 one-hot 向量(作者称这些常量中可能包含局部变量、函数参数、数据结构字段等关键信息)。
3.3 汇编语言模型
该模型分为三个任务:理解指令内部结构(MLM)、上下文窗口预测(CWP)、指令间数据依赖预测(DUP)。
3.3.1 MLM 任务
任务设置:在该任务中,随机选择 15% 的 tokens,将其中的 80% 进行 mask,10% 替换为其它 tokens,剩下的 10% 保持不变。

任务目标:输入 "mov 0x1; mov rdx ",让模型预测 "ebx" 和 "rbx"。
3.3.2 CWP 任务
任务设置:该任务为二分类任务,将目标指令前后 2 步指令都视为相关指令(一个窗口)(有点类似于 NSP 任务,但NSP 只关注相邻语句)

任务目标:输入 "mov ebx, 0x1" 与 "mov rdx, rbx" 这两条指令,模型判断两条指令是否在同一个窗口中。
3.3.3 DUP 任务
任务设置:给定一个指令对 $I_{1}$ 和 $I_{2}$,将 $I_{1} || I_{2}$ 视为正样本,$I_{2} || I_{1}$ 视为负样本。

任务目标:同样输入 "mov ebx, 0x1" 与 "mov rdx, rbx" 这两条指令,模型预测两条指令顺序是否发生交换(即数据依赖关系是否存在)。
4 实验分析
文中预训练数据集包含 x86-64 平台上不同版本的 Binutils4、Coreutils5、Diffutils6 和 Findutils7,并使用不同优化级别的 Clang8 和 GCC9 进行编译。共包含 3266 个二进制文件和 2.25 亿行指令。
文中实验结果如下(部分):
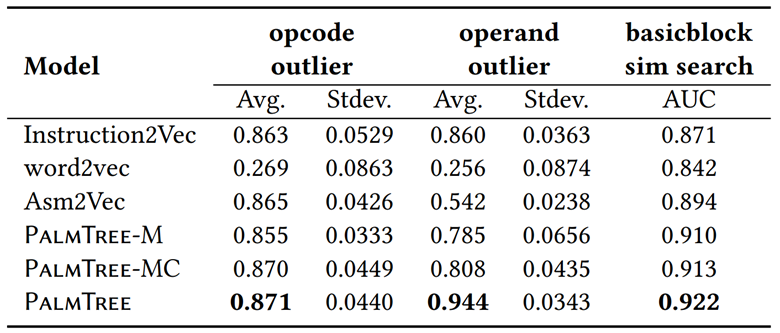
异常检测结果(Outlier Detection):
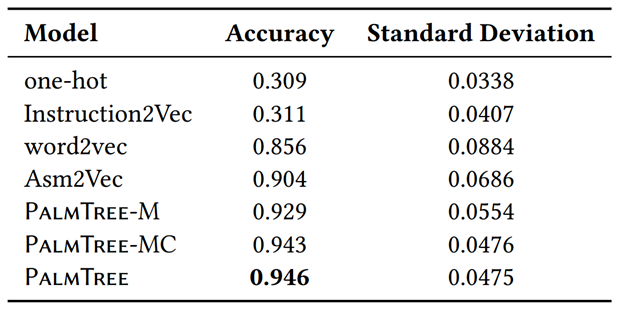
函数类型签名推断(FunctionType Signature Inference):
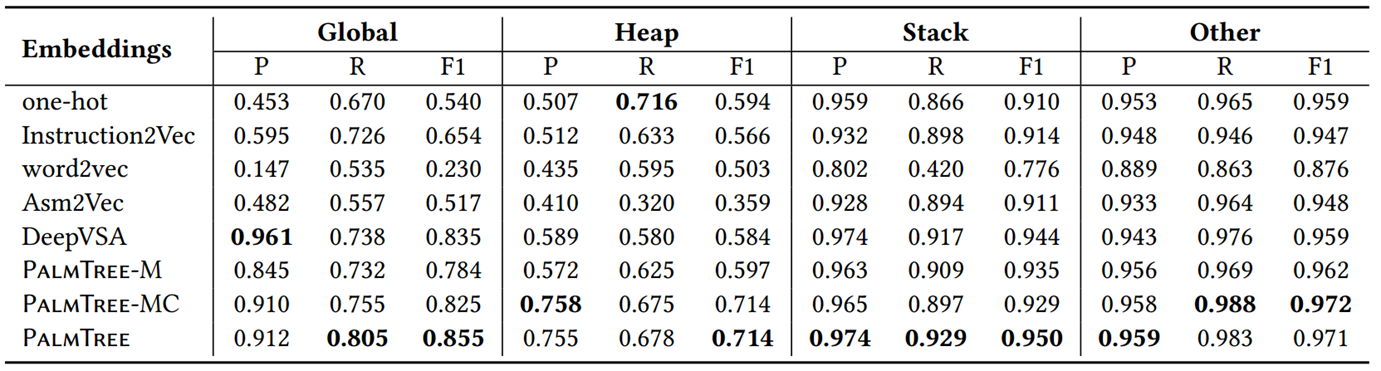
值集分析(Value Set Analysis,VSA):
5 全文总结
- 主要创新:指令对的采样方法、分词的技巧以及消除指令上下文信息噪声的手段。
- 缺陷:文章采用的数据集规模好像不够,难以覆盖所有的指令场景。
- 重要发现:编译器优化选项可能会导致控制流中的指令上下文中存在噪声,这种噪声会导致模型产生误报。
- 研究启示:后续有关汇编代码的嵌入工作可以直接使用该模型进行微调;文章的撰写逻辑和排版十分清晰,可以学习这种写作技巧。
6 原文信息
论文题目:PalmTree: Learning an Assembly Language Model for Instruction Embedding
论文出处:The ACM Conference on Computer and Communications Security (CCS 2021)
