- A+
所属分类:笔记
1. 开源组件(包含漏洞)
例如log4shell,spring4shell,复杂调用链,间接被调用,自己项目包含漏洞。
开源组件的可信度问题。
2. 软件供应链安全
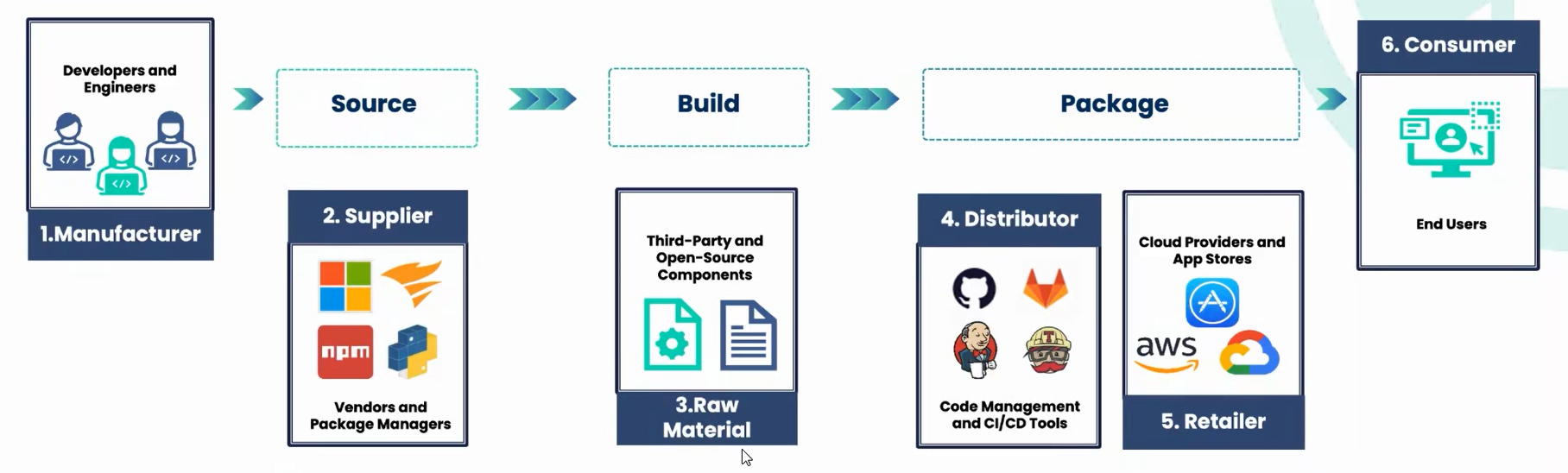
编译脚本注入恶意代码。
3. 开源安全所面临的挑战
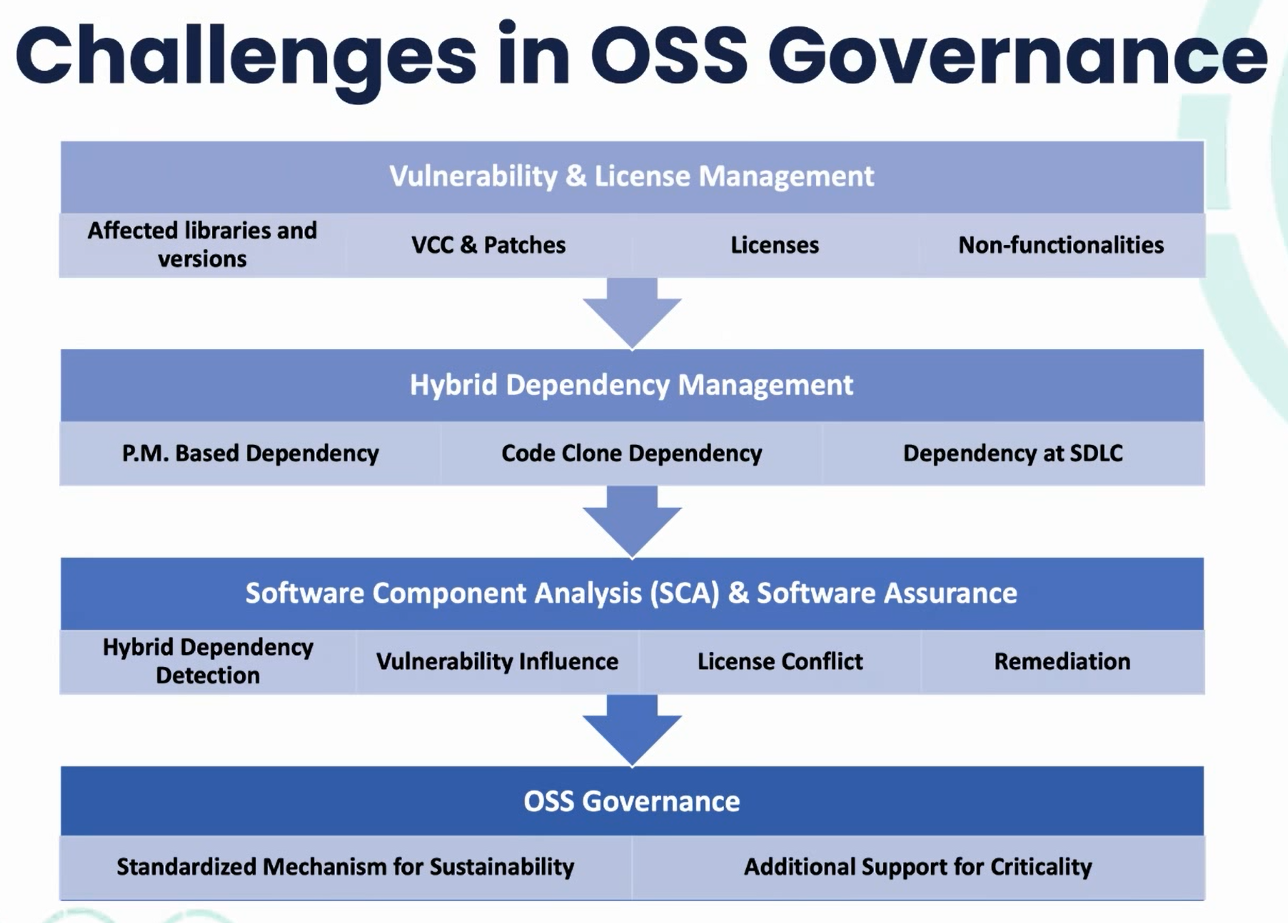
3.1 漏洞和许可证管理
- 保证开源组件漏洞数据的正确性、完整性和即时性。
- 目前没有公开网站能够提供上述数据。
3.2 复杂依赖管理
- 清楚知道开源组件的依赖关系。
- 如调用链、依赖图等。
以一种明确直白的方法或者算法将开源组件的这种依赖关系提取出来,放入数据库中。
3.3 软件成分分析
- 基于依赖关系等数据,如何去做开源软件成分分析的工作?
- 目前市场上99%的工具无法做完整的软件组件分析。
3.4 开源软件治理
构建开源社区,共同解决安全管理、运维等问题。
4. 开源安全的相关研究

4.1 MVP(USENIX 20)
核心思想:偏向于基于漏洞行为(语义)的检测,而不是基于语法。通过关键语义函数的位置,进行前向和后向程序切片,找到与漏洞相关的statements(语句),这些语句作为表示漏洞行为的代码。
- 在漏洞克隆检测中,即使改变代码(传统漏洞克隆检测方法失效),只要漏洞行为存在,依旧可以预测到漏洞。
- 用于收集准确的漏洞函数与开源组件版本的映射关系(NVD中漏洞影响版本的范围,80%有误)—— 漏洞范围确认。

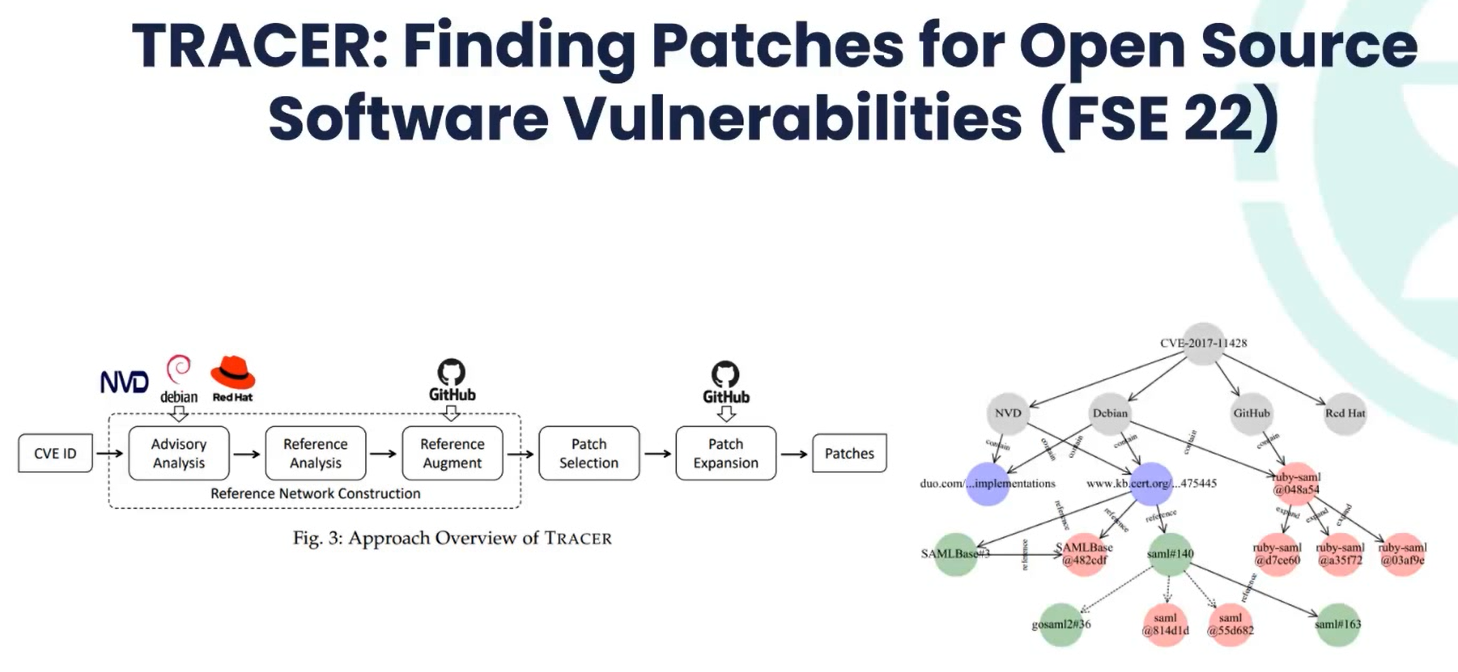
4.2 TRACER(FSE22)
自动化整合、收集漏洞函数补丁。
核心方法:使用debian advisory分析器,进行依赖分析和一些链接的跳转,找到一些潜在的漏洞,然后push到github中进行补丁挑选和扩展。
4.3 LiDetector(TOSEM 22)
代码许可证信息判断,许可证冲突。
分析了1846个开源项目,发现1346个项目存在许可证问题,开源组件会复制并使用其它代码,这些代码包含许可证信息,导致引入的代码的许可证与自己项目的许可证冲突。

4.4 ATVHunter
二进制代码第三方库检测,也即二进制代码克隆,其步骤大致为:开源组件->二进制代码->签名->数据库->映射漏洞->待检测的二进制代码->提取信息->与数据库做克隆检测。
难点:源代码编译为二进制代码的过程中编译器不同、编译选项不同、可能加入混淆算法,在此场景下,如何保证克隆算法的鲁棒性?
核心思路:高阶代码逻辑,Java层面加入混淆算法后,其核心CFG通常保持不变,通过提取CFG信息,变成签名并放入到漏洞数据库中。

4.5 ModX
代码的不同模块有很强的耦合性,代码相似性聚类,将软件逆向运用到第三方库检测上。
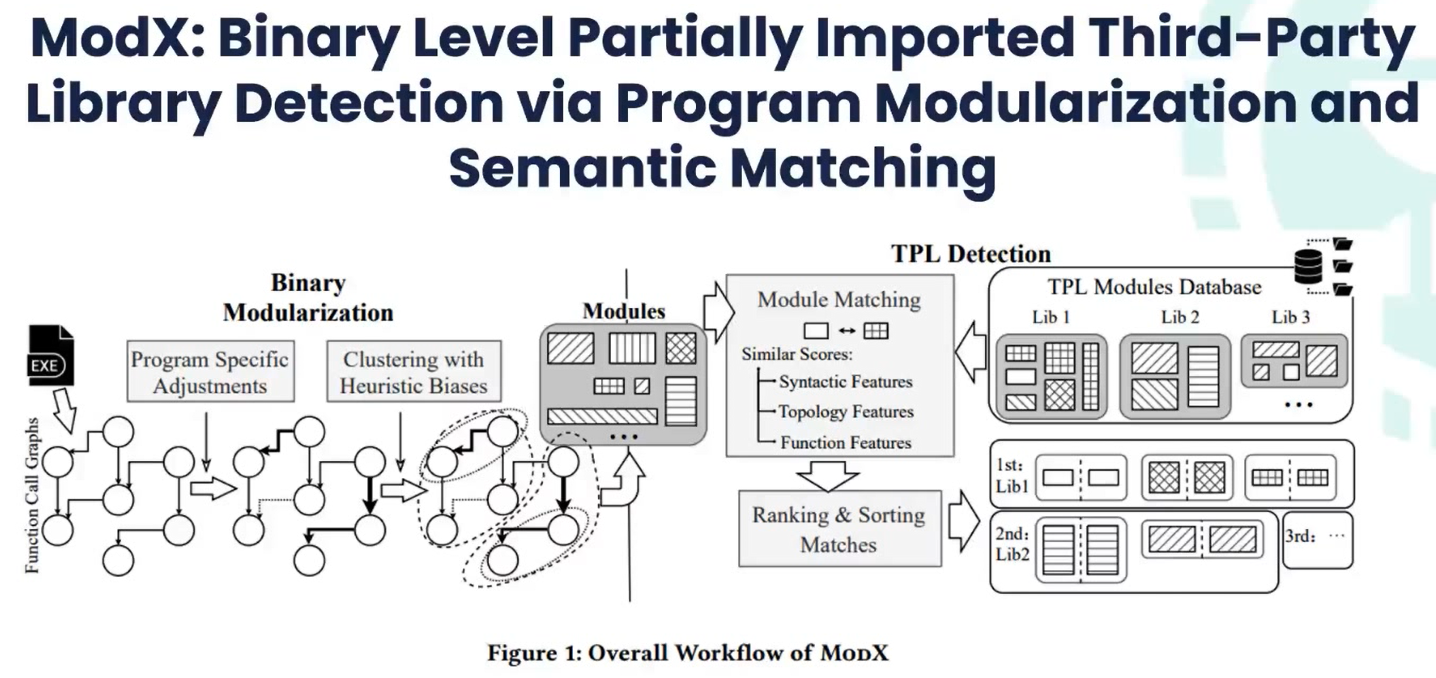

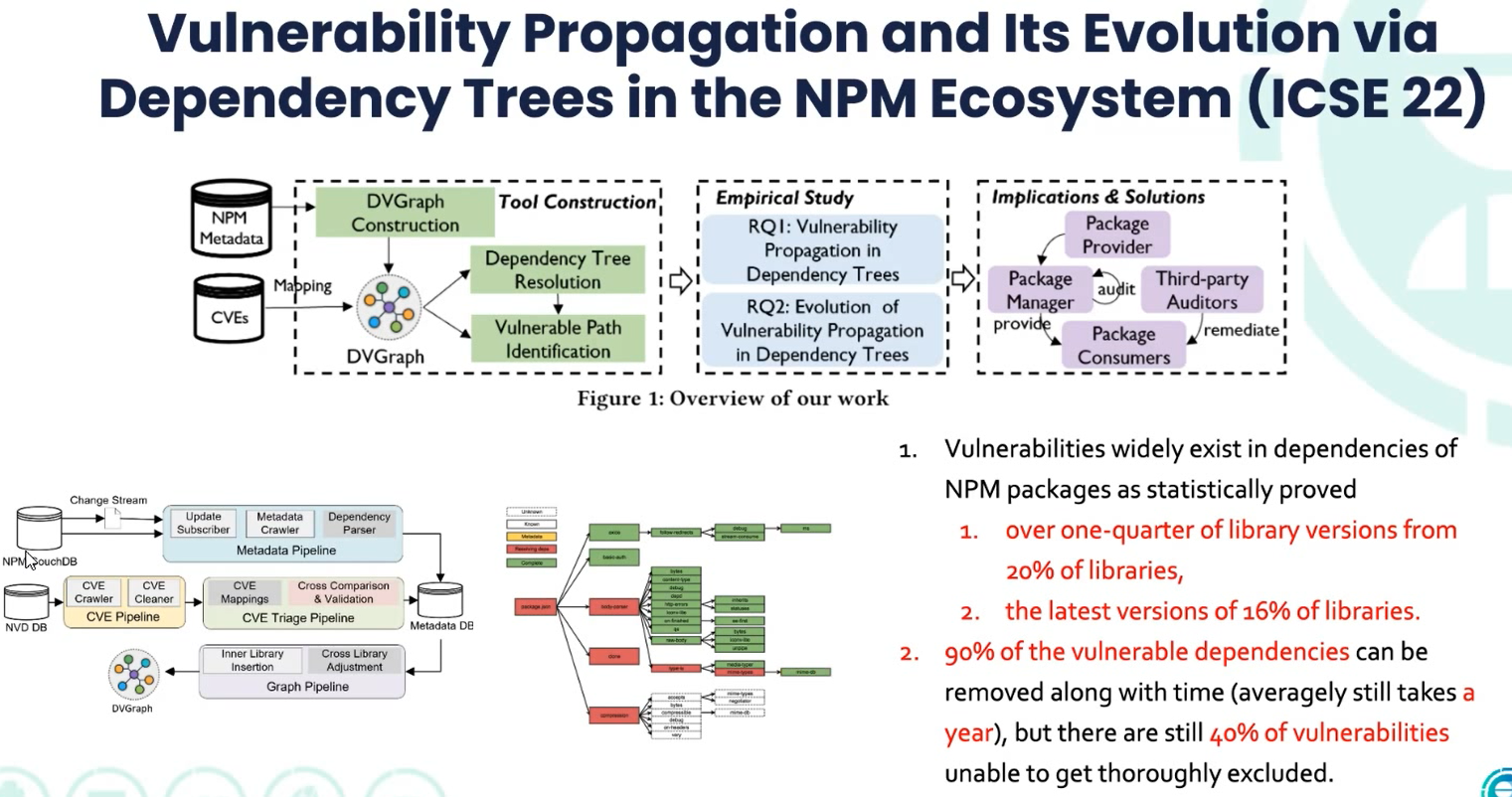
4.7 Dependence trees
理解开源组件的依赖关系。
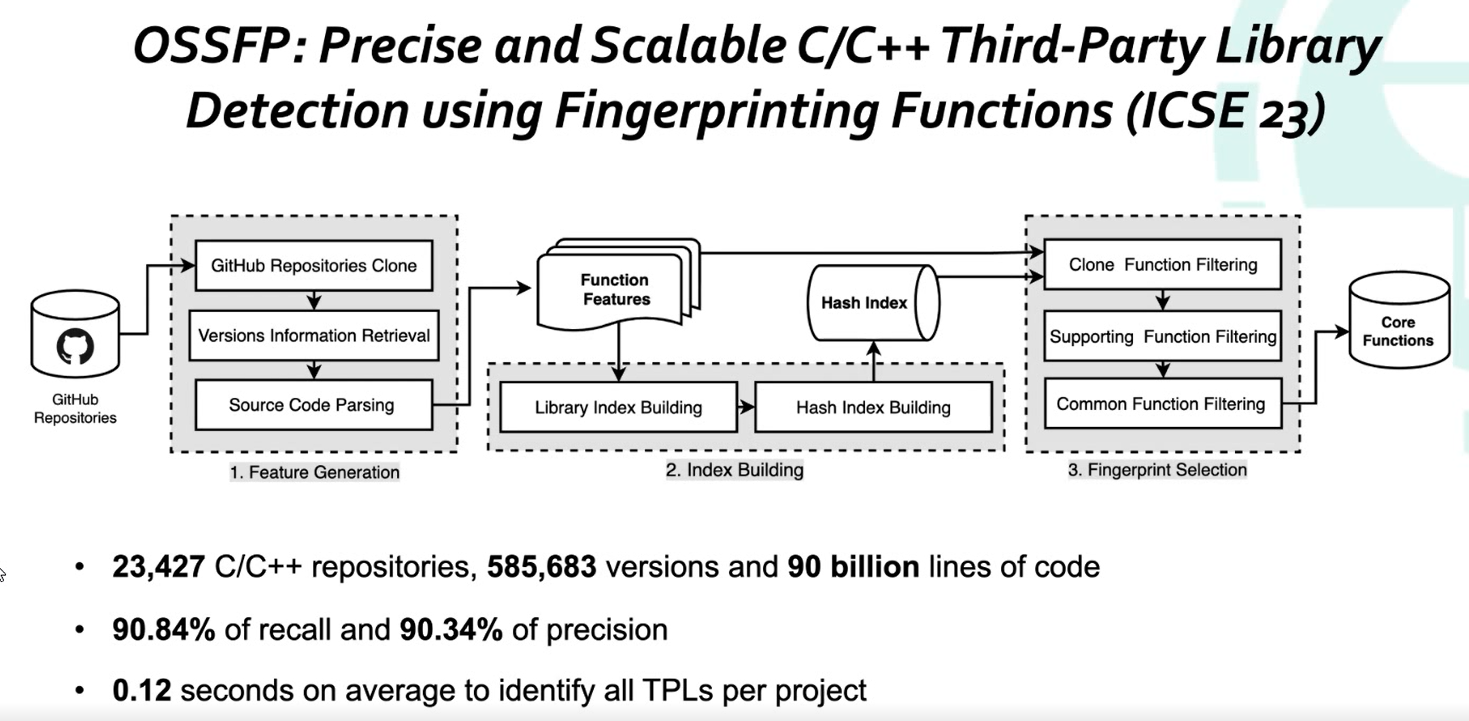
4.8 OSSFP
C/C++第三方库检测
4.9 SAST

4.10 Version detection
大规模组件不同版本的兼容性检测。