- A+
所属分类:笔记
人工智能安全事件
- 对抗攻击误导模型决策错误。
- 深度伪造视频。
- 歧视与偏见。
AI安全
1.设计阶段。
数据收集过程中的偏见,数据标注的偏见,结果解释的偏见,设计算法采取准则的偏见。(图片搜索中“护士”大部分是女性;语音识别中,黑人错误率明显高于白人。)
2.训练阶段
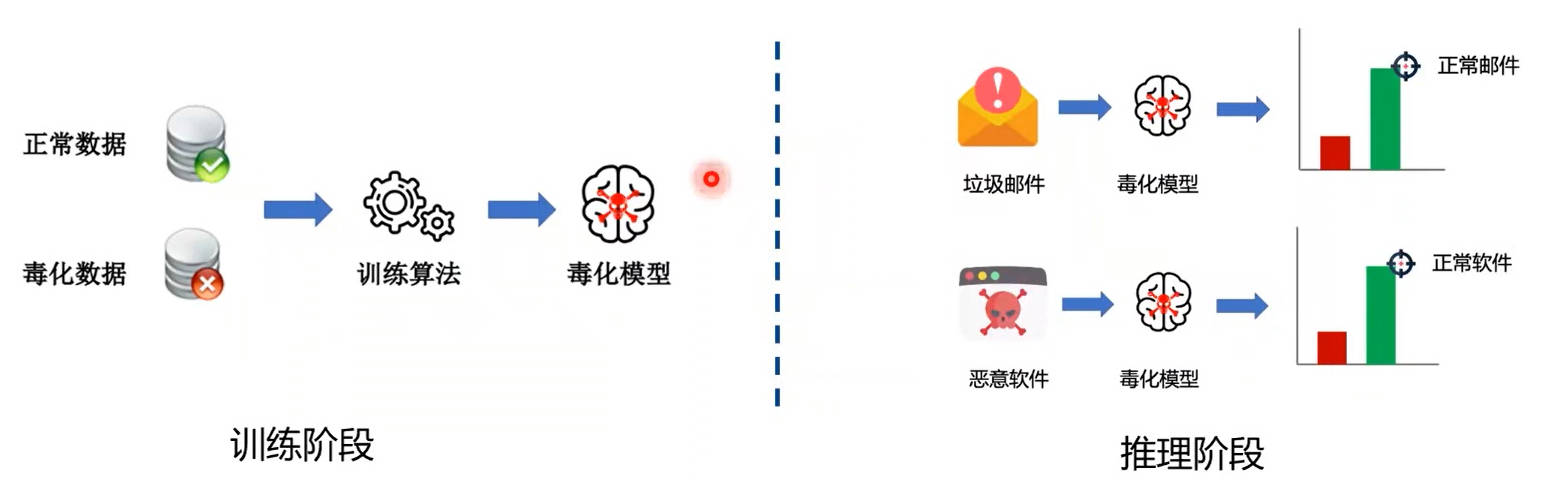
数据投毒:
攻击者将少量精心设计的中毒样本添加到模型的训练数据集中,利用训练或者微调过程使得模型中毒,从而破坏模型的可用性或完整性,最终导致模型在测试阶段表现异常。例如将垃圾邮件/恶意软件识别为正常邮件/软件。
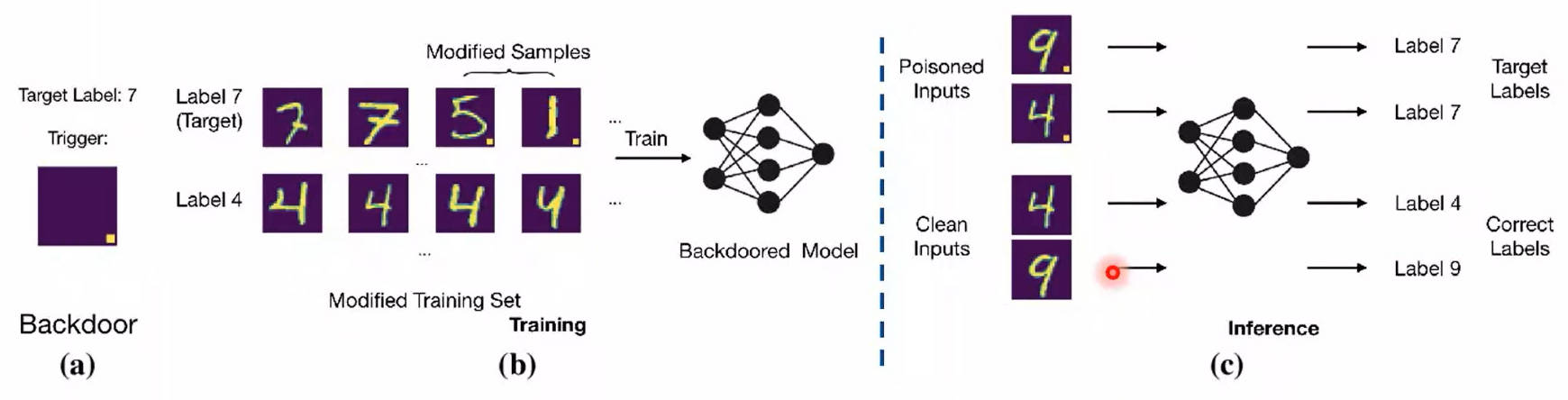
后门攻击:
- 在训练数据中加入少量的带触发器的毒化数据,破坏模型的训练完整性。
- 面对正常输入,模型预测无异常;面对包含触发器的输入数据,模型预测结果被恶意篡改。
如下图(b)中训练数据中的数字图片"5"和"1"中的黄色小块,攻击者将其标记为label 7,训练得到的后门模型在预测阶段会得到错误结果(如下图(c)中将数字9和4错误预测为数字7)。
3.执行阶段
对抗攻击:
- 攻击者对输入加入精心设计的扰动,使模型得出错误的结果。
- 加入的扰动难以被辨识,隐蔽性很强。
- 根据攻击者意图,对抗攻击可分为有目标攻击和无目标攻击。
- 根据攻击者所能获取的信息,对抗攻击分为白盒攻击、灰盒攻击。
例如下图中的音频中加入噪声并乘以0.01,虽然音频改变微乎其微(人耳听不出任何区别),但在语音识别设备中可能将"How are you?"识别为"Open the door"。

AI安全要素
保密性、完整性、鲁棒性、隐私性、公平性。
AI安全问题的原因分析
数据依赖性强、模型可解释性不足
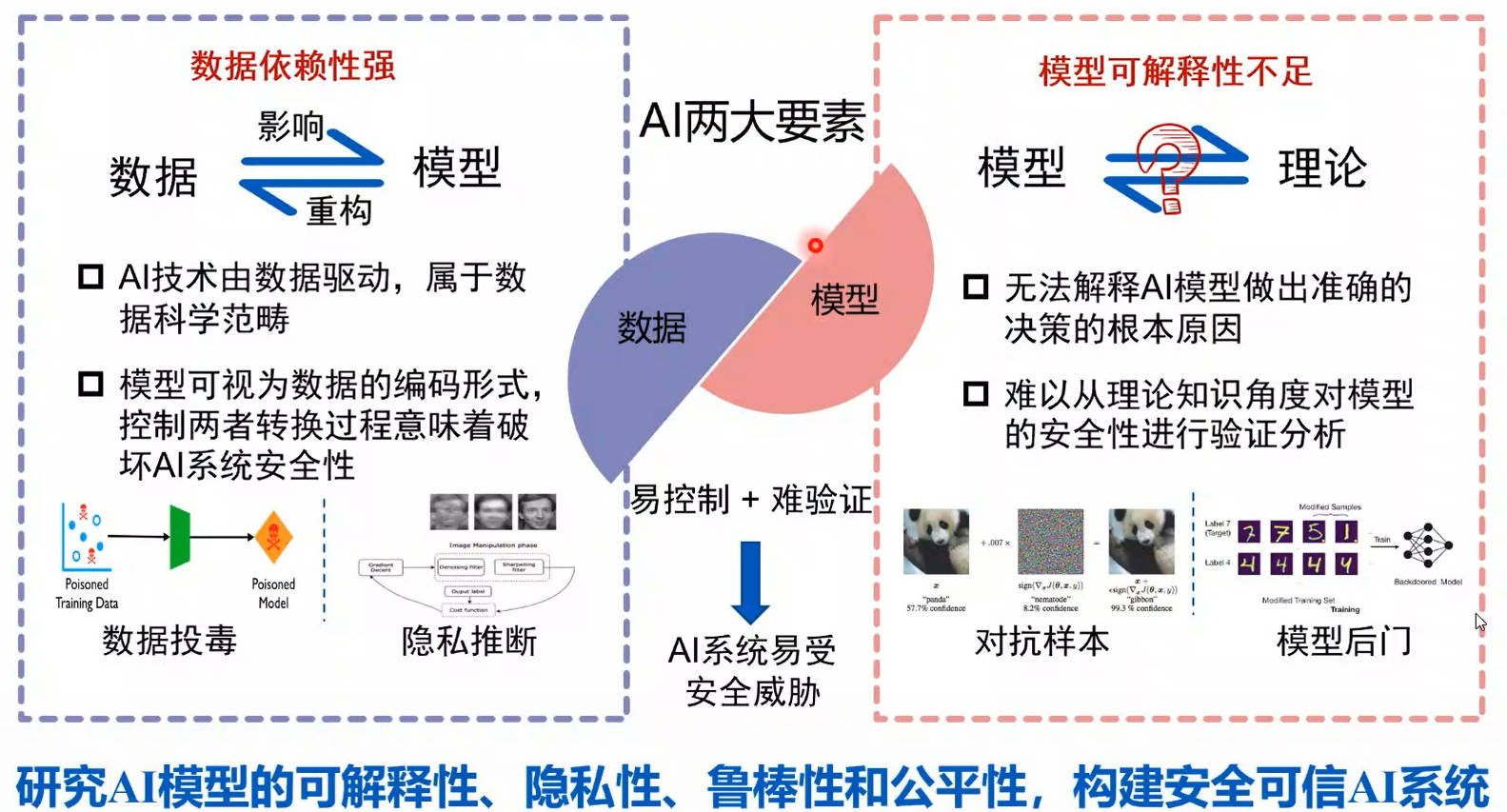
可信AI(Trustworthy AI)是抵御风险的关键能力
隐私保护、鲁棒性/稳定性、可解释性、公平性是【可信AI】的四大基本原则。
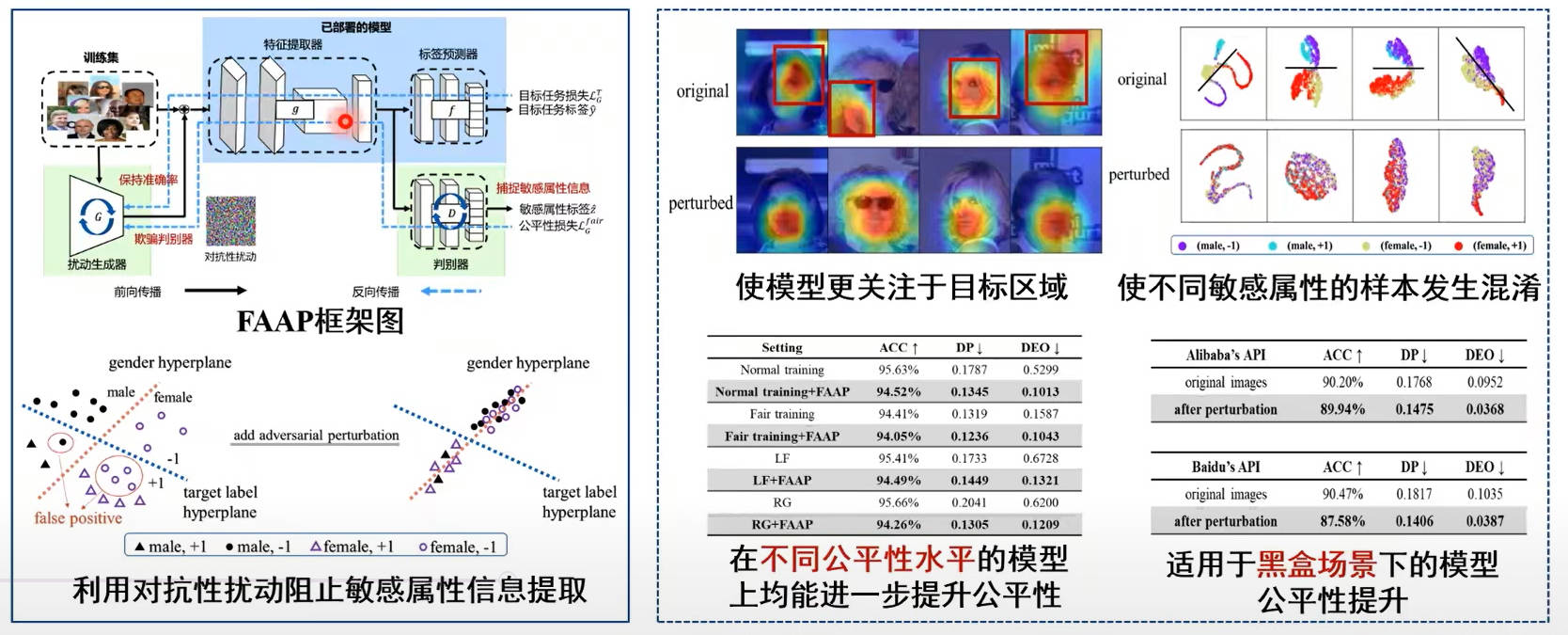
模型公平性提升
提出了基于对抗性扰动的公平性提升技术,通过阻止模型提取敏感属性相关信息且保留目标任务相关信息,在不改变已部署模型的情况下提升系统公平性。
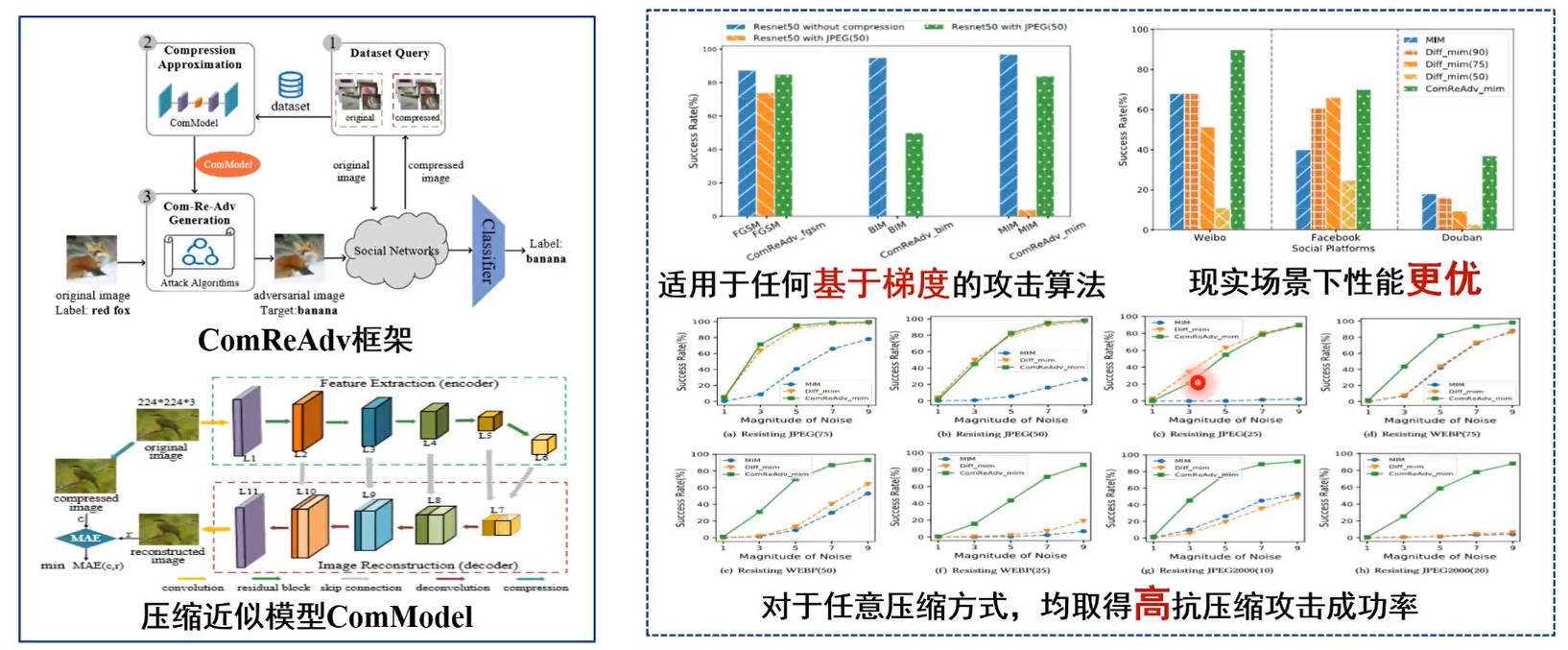
抗压缩对抗样本
提出了基于压缩近似模型的抗压缩对抗样本生成技术,在对抗样本优化时引入压缩近似模型,首次实现在社交平台未知压缩方式下的抗压缩对抗图像生成。
应用:在将自己的图片发布至社交平台之前,可以使用提出的模块将原始图片处理成为抗压缩的图片,这样即使别人在爬取到我们的图片数据后,也无法用作深度学习的训练数据,从而保护自己的隐私。