
- A+
1. Word2vec是啥?
在聊 Word2vec 之前,先聊聊 NLP (自然语言处理)。在NLP里面,最细粒度的是 词语,词语 组成句子,句子再组成段落、篇章、文档。所以处理 NLP 的问题,首先就要拿词语开刀。举个简单例子,判断一个词的词性,是动词还是名词。用机器学习的思路,我们有一系列样本(x,y),这里 x 是词语,y 是它们的词性,我们要构建 f(x)->y 的映射,但这里的数学模型 f(比如神经网络、SVM)只接受数值型输入,而 NLP 里的词语,是人类的抽象总结,是符号形式的(比如中文、英文、拉丁文等等),所以需要把他们转换成数值形式,或者说——嵌入到一个数学空间里,这种嵌入方式,就叫词嵌入(word embedding),我们要谈的Word2vec,就是词嵌入(word embedding) 的一种。
大部分的有监督机器学习模型都可以归纳为:
f(x) -> y在 NLP 中,把 x 看做一个句子里的一个词语,y 是这个词语的上下文词语,那么这里的 f,便是 NLP 中经常出现的语言模型(language model),这个模型的目的,就是判断 (x,y) 这个样本,是否符合自然语言的法则,更通俗点说就是:词语 x 和词语 y 放在一起,是不是人话。
Word2vec 正是来源于这个思想,但它的最终目的,不是要把 f 训练得多么完美,而是只关心模型训练完后的副产物——模型参数(这里特指神经网络的权重),并将这些参数,作为输入 x 的某种向量化的表示,这个向量便叫做——词向量。
下面举个例子,如何用Word2vec寻找相似词:

- 有一句话:【你们说吴彦祖帅的一批】,如果输入x是【吴彦祖】,那么y可以是【你们】,【说】,【帅的】,【一批】这些词语。
- 另一句话:【你们说我帅的一批】,如果输入x是【我】,那么可以很清楚的发现这里的y和上面的一样。
- 从而可以得出一个结论:f(吴彦祖) = f(我) = y,也即 吴彦祖 = 我。
2. Word2vec的两种训练模式
2.1 Skip-gram 模型(Continuous Skip-gram Model)
Skip-gram模型:如果是用一个词语作为输入,来预测它周围的上下文,那这个模型叫做【Skip-gram 模型】。
____ ____ 我 ____ ____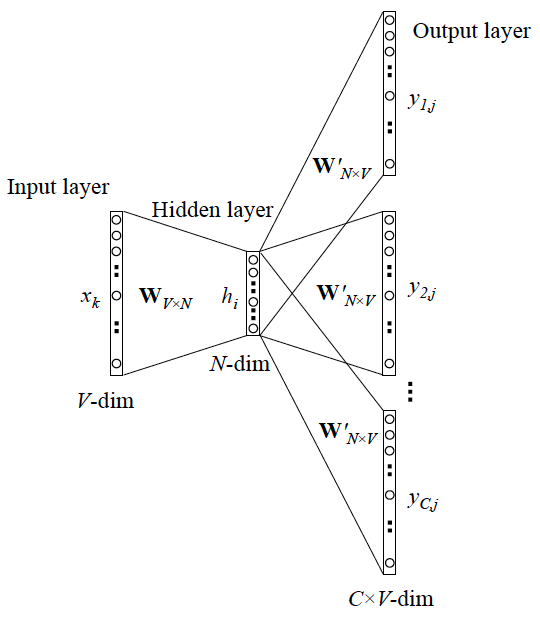
可以看成是 单个x->单个y 模型的并联,cost function 是单个 cost function 的累加(取log之后)。
2.2 CBOW 模型(Continuous Bag-of-Words Model)
CBOW 模型:如果是拿一个词语的上下文作为输入,来预测这个词语本身,则是 【CBOW 模型】。
吴彦祖 没有 ____ 长的 帅气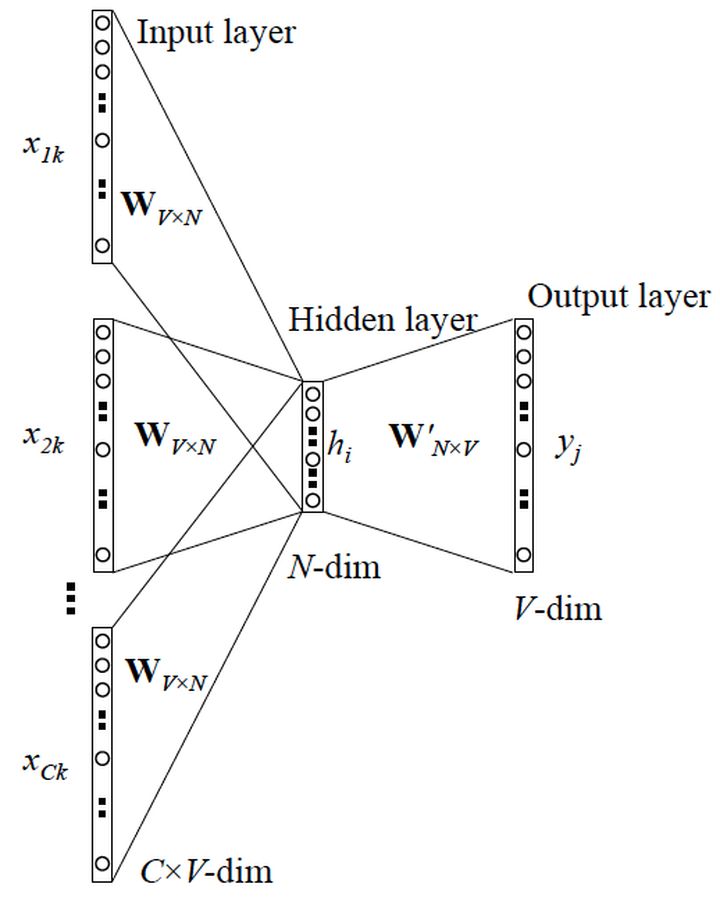
这里的输入变成了多个单词,所以要对输入处理下(一般是求和然后平均),输出的 cost function 不变
3. One-Hot Encoder(独热编码)
独热编码又称一位有效编码,其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。举个例子,假设我们有四个样本(行),每个样本有三个特征(列),如下图:
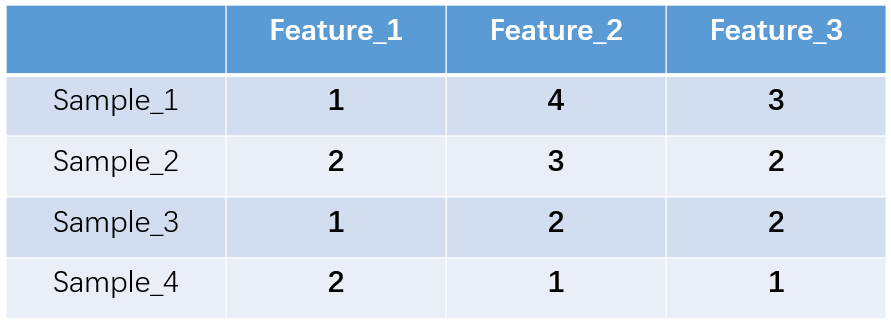
feature_1有两种可能的取值,比如是男/女,这里男用1表示,女用2表示。feature_2 和feature_3各有4种取值(状态)。one-hot编码就是保证每个样本中的单个特征只有1位处于状态1,其他的都是0。上述状态用one-hot编码如下图所示:
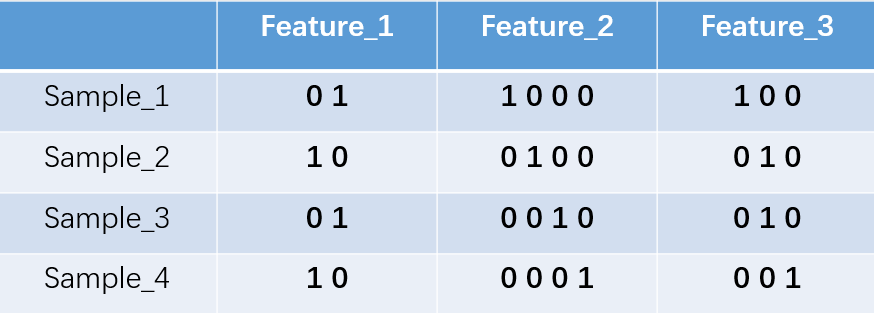
考虑一下的三个特征:
["male", "female"]
["from Europe", "from US", "from Asia"]
["uses Firefox", "uses Chrome", "uses Safari", "uses Internet Explorer"]将它换成独热编码后,应该是:
feature1=[01,10]
feature2=[001,010,100]
feature3=[0001,0010,0100,1000]4. Word2vec
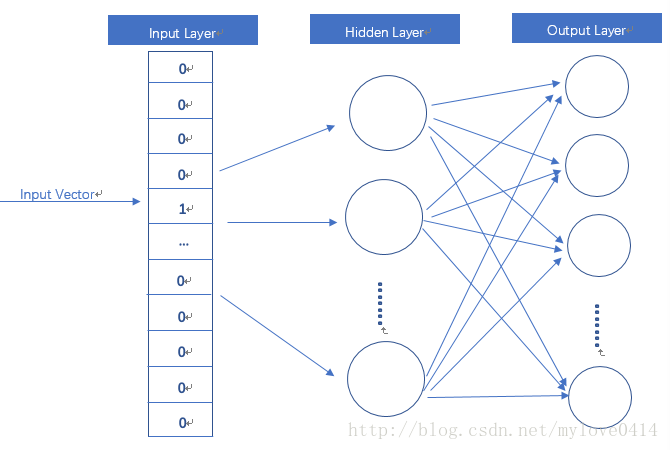
Word2vec模型其实就是简单化的神经网络,上文所说的输入的 x 就是One-Hot Vector,Hidden Layer没有激活函数,也就是线性的单元。Output Layer维度跟Input Layer的维度一样,用的是Softmax回归。当这个模型训练好以后,我们并不会用这个训练好的模型处理新的任务,我们真正需要的是这个模型通过训练数据所学得的参数,例如隐层的权重矩阵。
这个模型是如何定义数据的输入和输出呢?就是上面提到的 CBOW 与 Skip-Gram 两种模型。CBOW对小型数据库比较合适,而Skip-Gram在大型语料中表现更好。
百度百科:
Word2vec,是一群用来产生词向量的相关模型。这些模型为浅而双层的神经网络,用来训练以重新建构语言学之词文本。网络以词表现,并且需猜测相邻位置的输入词,在word2vec中词袋模型假设下,词的顺序是不重要的。训练完成之后,word2vec模型可用来映射每个词到一个向量,可用来表示词对词之间的关系,该向量为神经网络之隐藏层。参考:
https://www.jianshu.com/p/471d9bfbd72f
https://zhuanlan.zhihu.com/p/26306795
https://baike.baidu.com/item/Word2vec/22660840?fr=aladdin
https://easyai.tech/ai-definition/word2vec/
想要深入探讨的可以传送到:https://www.cnblogs.com/peghoty/p/3857839.html
